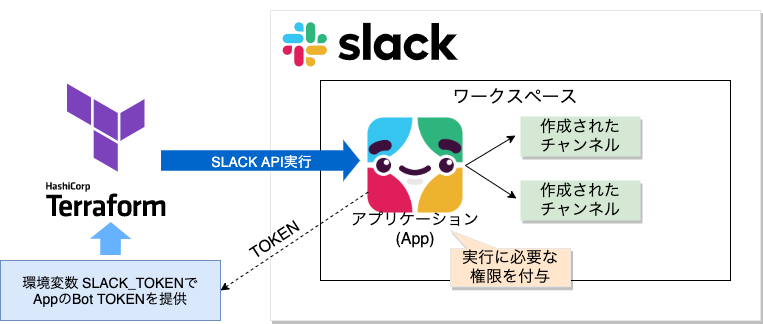
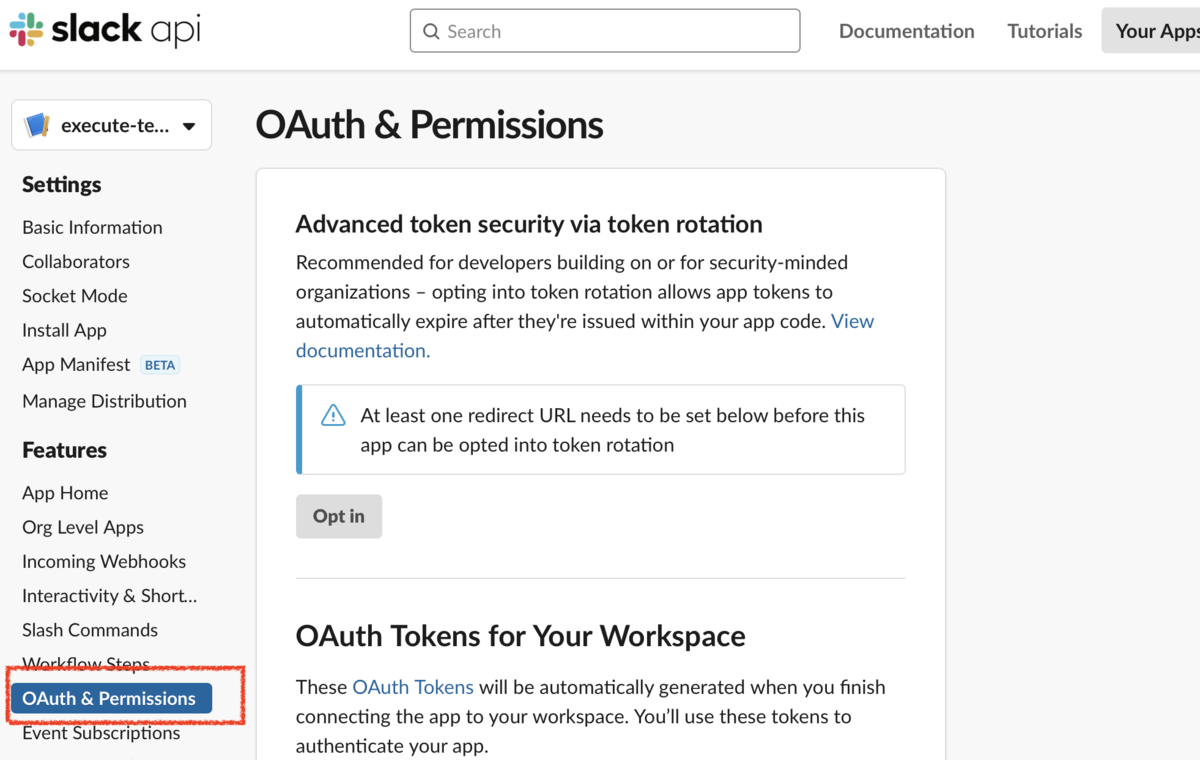
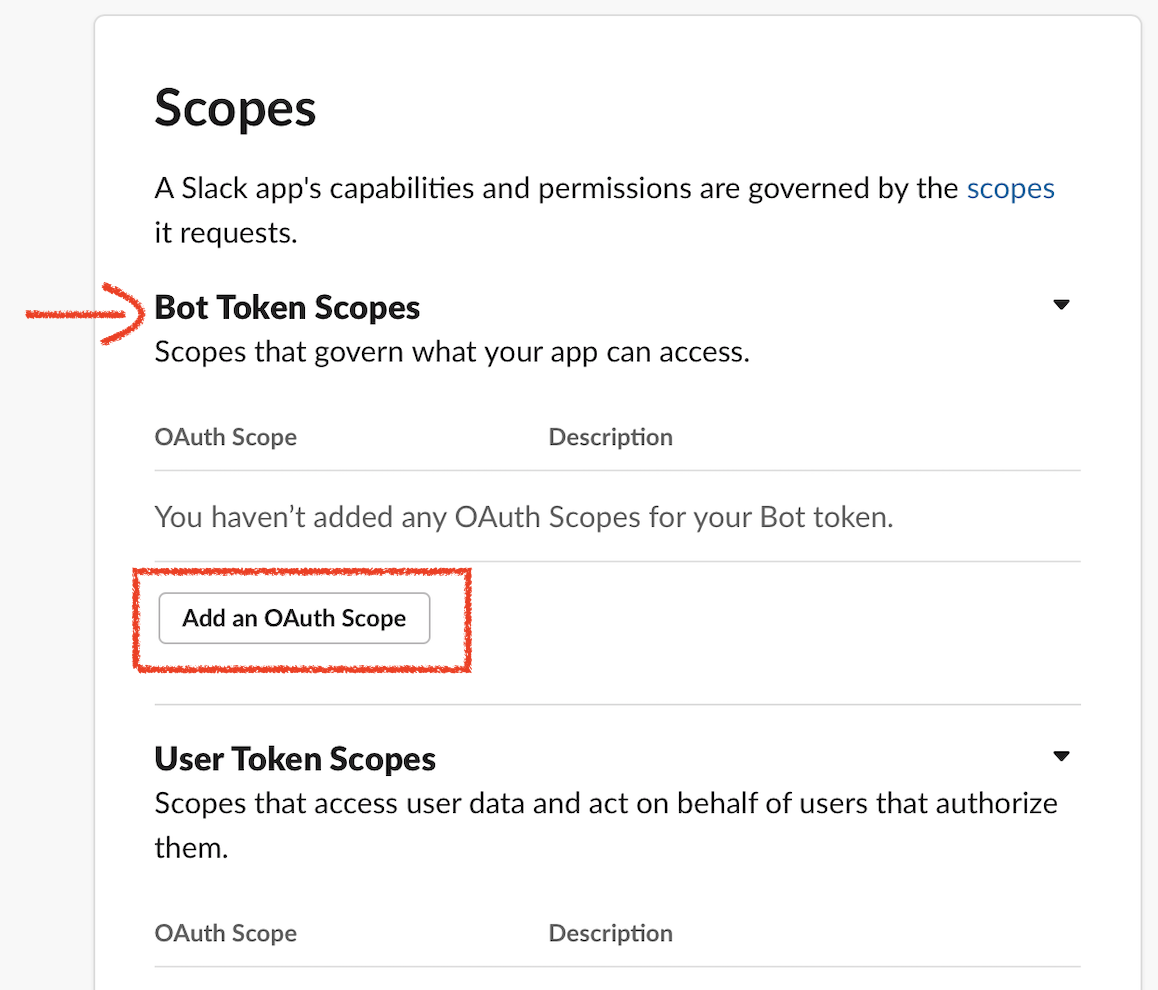
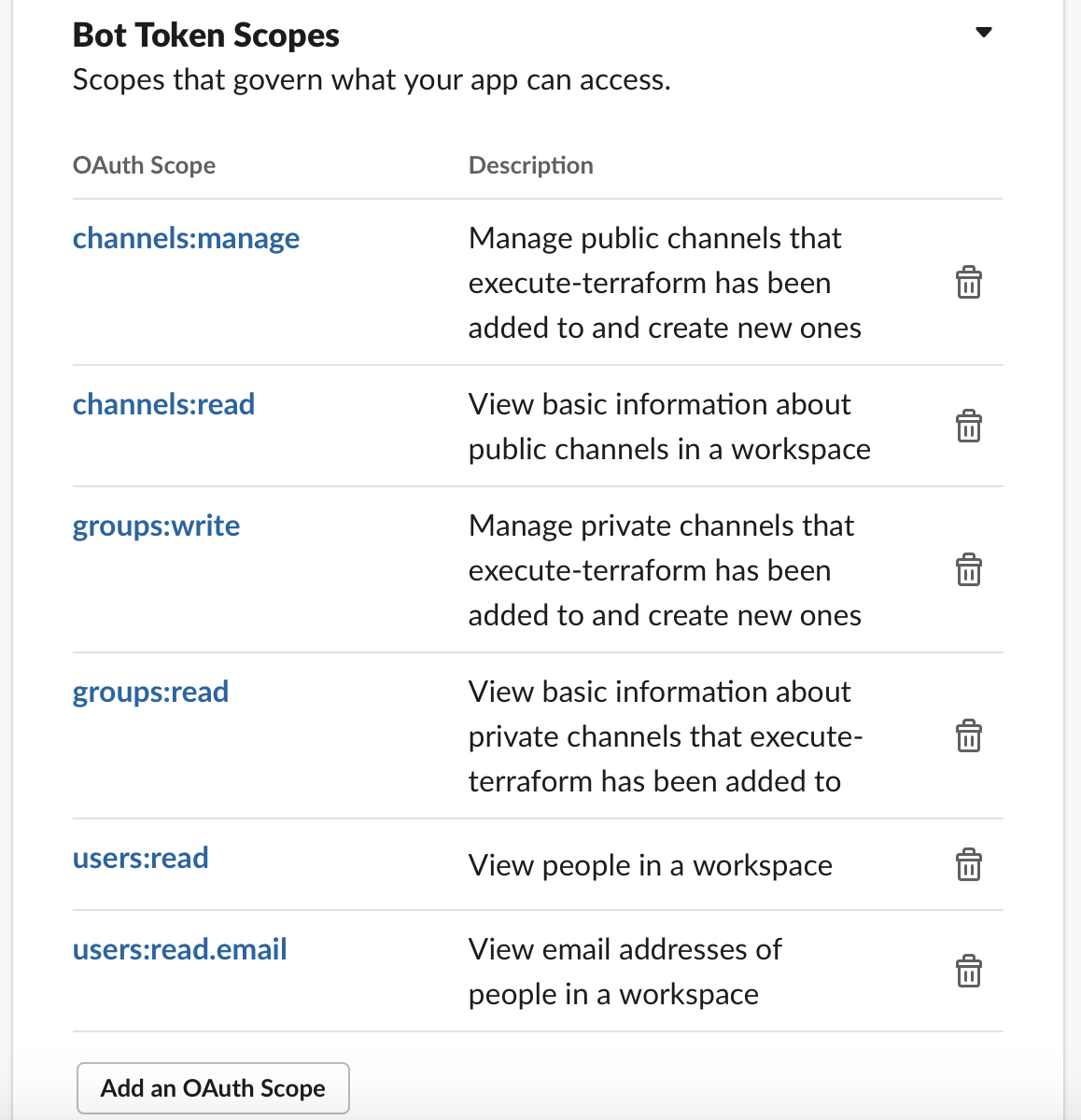
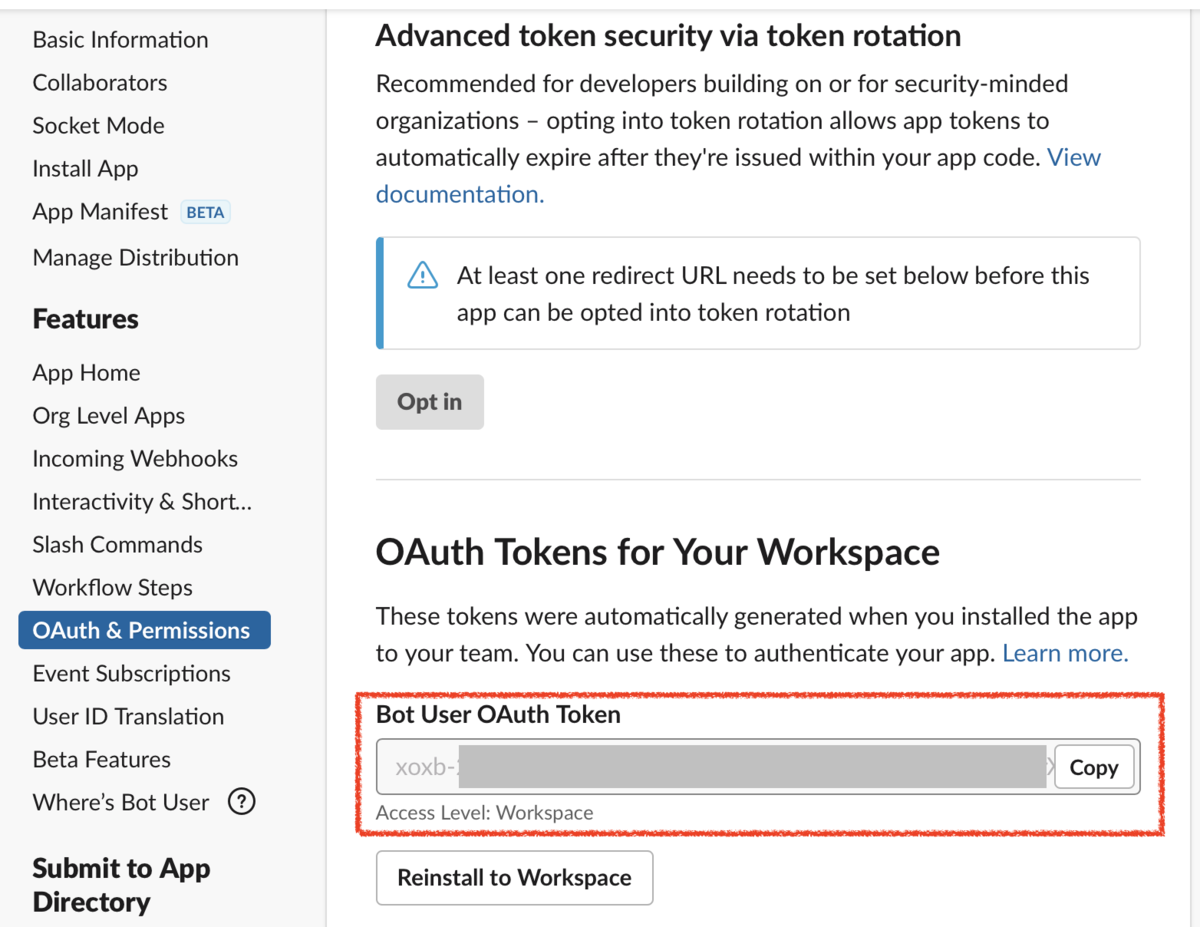
Lambdaで特定のロググループ & ログストリームにログ出力するコードのサンプルです。
この例では、eventの内容をLogsに出力しています。
コードは以下の記事の内容をベースに一部最適化してます。
import json
import time
import boto3
logGroupName = "security-alaert"
logStreamName = "development"
def lambda_handler(event, context):
client = boto3.client('logs')
put_logs(client, logGroupName, logStreamName, "Received event:{0}".format( json.dumps(event)))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
def put_logs(client, group_name, stream_name_prefix, message):
try:
log_event = {
'timestamp': int(time.time()) * 1000,
'message': message
}
exist_log_stream = True
sequence_token = None
while True:
break_loop = False
try:
if exist_log_stream == False:
try:
client.create_log_group(logGroupName=group_name)
except client.exceptions.ResourceAlreadyExistsException:
pass
client.create_log_stream(
logGroupName = group_name,
logStreamName = stream_name_prefix)
exist_log_stream = True
client.put_log_events(
logGroupName = group_name,
logStreamName = stream_name_prefix,
logEvents = [log_event])
break_loop = True
elif sequence_token is None:
client.put_log_events(
logGroupName = group_name,
logStreamName = stream_name_prefix,
logEvents = [log_event])
else:
client.put_log_events(
logGroupName = group_name,
logStreamName = stream_name_prefix,
logEvents = [log_event],
sequenceToken = sequence_token)
break_loop = True
except client.exceptions.ResourceNotFoundException as e:
exist_log_stream = False
except client.exceptions.DataAlreadyAcceptedException as e:
sequence_token = e.response.get('expectedSequenceToken')
except client.exceptions.InvalidSequenceTokenException as e:
sequence_token = e.response.get('expectedSequenceToken')
except Exception as e:
print(e)
if break_loop:
break
except Exception as e:
print(e)