こちらはAWS Containers Advent Calendar 2020の13日目の記事です。
本記事は個人の意見であり、所属する組織の見解とは関係ありません。
とてもこまか〜い話ですが、Amazon ECSのタスク定義設定ではCPUのリソース設定に関して以下の2つのパラメータがあります。この2つのパラメータがどんな挙動をするのか気になりましたのでドキュメントと実機での挙動確認から調べてみました。最後にOSレベルですが素潜りもしてみました。(時間があればcgroupのコードも確認したかったのですが時間がなく、残念)
- タスクサイズのCPU: タスクに使用される CPU量。
- コンテナ定義レベルでのCPUユニット: コンテナ用に予約した cpu ユニットの数

長い記事になってしまったので調査結果の結論を先に行ってしまうと、以下の通りになりました。
- コンテナのCPUユニットは、
- 各コンテナに対するCPU制限で、各コンテナ合計値に対する設定値の割合で利用可能なCPUリソースが決まる
- ECSはdockerのCPU Sharesを利用し実現しており、dockerはLinuxの場合はcgroupの
cpu.sharesで機能を実現している - cgroupの
cpu.shares仕様で、CPUの競合が発生していない時はコンテナのCPUユニットによる制限は発動しない
- タスクサイズのCPUは、
- 単一のタスクが対象となり、設定値はハードリミットになる
- 実機確認の限りでは、Linuxではcgroupの
cpu.cfs_period_usとcpu.cfs_quota_usで機能を実現しているように見える
なお本記事に記載している内容は、下記前提で記載していますのでご了承ください。
- ECS + EC2(Linux)構成で確認しています。Fargate構成やEC2(Windows)構成の場合は本記事の内容と異なる可能性があります。
- 執筆時点(2020年12月13日)での実機環境での挙動確認の結果に基づいて記事を作成しています。
はじめにAmazon ECSとCPU設定について
Amazon ECSとは
Amazon Elastic Container Service (Amazon ECS) は、フルマネージド型のコンテナオーケストレーションサービスで、多数の仮想マシンを束ねてコンテナを一元管理運用するためのサービスになります。Amazon ECSは一元管理する機能ですので、実際にコンテナを実行する環境は別に必要となります。現時点でコンテナの実行環境としては、EC2インスタンスか、マネージドサービスのAWS Fargateのどちらかが選択できます。(今開催されているAWS re:Invent2020でAmazon ECS Anywhereが発表され、2021年にはどこにでもデプロイすることが可能となりますね)
Amazon ECSについて詳しく知りたいという方は、こちらのBlackBeltが参考になるかと思いますのでご参照ください。
aws.amazon.com
Amazon ECSのタスクとコンテナの関係
おさらいをかねて、Amazon ECSのタスクとコンテナの関係を振り返ります。
- ECSタスク : Amazon ECSで管理する最小単位。Amazon ECSはタスク単位でコンテナの立ち上げ/立ち下げを行います。タスクには一つ以上のコンテナが含まれています。また単一のタスクは、同一のホストOS上で稼働させます。一つのタスクを2台以上のホストOSにまたいで実行することはできません。ECSタスクの構成は、タスク定義(Task definition)で設定されます。
- コンテナ: dockerのコンテナです。ECSタスクの中に包含されています。単一のコンテナを起動するには、タスクの定義に1 つのコンテナのみ定義することで実現します。

まずはドキュメントで確認
まずはAmazon ECSの開発者ガイドでそれぞれのパラメータの仕様を確認してみます。ドキュメントでは、Amazon ECSタスク定義に説明があり、それぞれ下記に設定の記載があります。
- タスクサイズのCPU -> タスクサイズのcpu
- コンテナのCPUユニット -> コンテナ定義->詳細コンテナ定義パラメータ-> 環境のcpu
上記のドキュメントの内容を表にまとめると以下のようになります。
| 設定 | 適用範囲 | 制限 | 空きCPUリソース がある場合の挙動 |
備考 |
|---|---|---|---|---|
| タスクサイズのCPU | タスク | ハード制限 | 上限を超えて 割り当てられない |
|
| コンテナのCPUユニット | タスク内のコンテナ | 各コンテナ合計値 に対する 割合で評価 |
設定値を超えて CPUをコンテナに割り当て |
dockerの--cpu-sharesを利用 |
また上記以外に下記仕様もあります。
- 双方の設定とも、1vCPU = 1024として設定を行う
- タスク内の各コンテナに設定したCPUユニットの合計値が、タスクサイズのCPU以内であること
これらの内容を図にまとめると以下のようになります。

実機で挙動確認
それではドキュメントの内容を実機で確認して行きたいと思います。
なお今回は下記環境で挙動確認をしています。
- バージョン
- ECS Agentバージョン: 1.48.1
- dockerバージョン: 19.03.13-ce
- ワーカー構成
- 起動タイプ: EC2インスタンス
- AMI: Amazon ECS-optimized Amazon Linux 2 AMI(amzn2-ami-ecs-hvm-2.0.20201209-x86_64-ebs)
- OS: Amazon Linux2(kernel version = 4.14.209-160.335.amzn2.x86_64)
- EC2インスタンス構成
- m5.large or m5.xlargeを利用
- CPUオプションで1core=1threadに設定(CPUのHyperThreadの影響を排除するため)。従って今回の構成でのOS上のCPU数は以下の通りとなります。
- m5.large -> OSが認識するCPUは、1個
- m5.xlarge -> OSが認識するCPUは、2個
コンテナのcpuユニットの挙動を見てみた
では最初に、コンテナのcpuユニットのみ設定した状態での挙動を見てみます。
(1)ホストOSが1CPUの場合
- ホストOS構成: m5.large(1スレッド/core設定) x 1ノード
- OSが認識するCPU数: 1個
- タスク構成
- container1: CPU Unit =
768 - container2: CPU Unit =
256
- container1: CPU Unit =
タスク内に2つのコンテナがあり、CPU配分を3/4(75%)と1/4(25%)に設定します。このタスクを1タスクのみ起動します。絵にすると以下の通です。
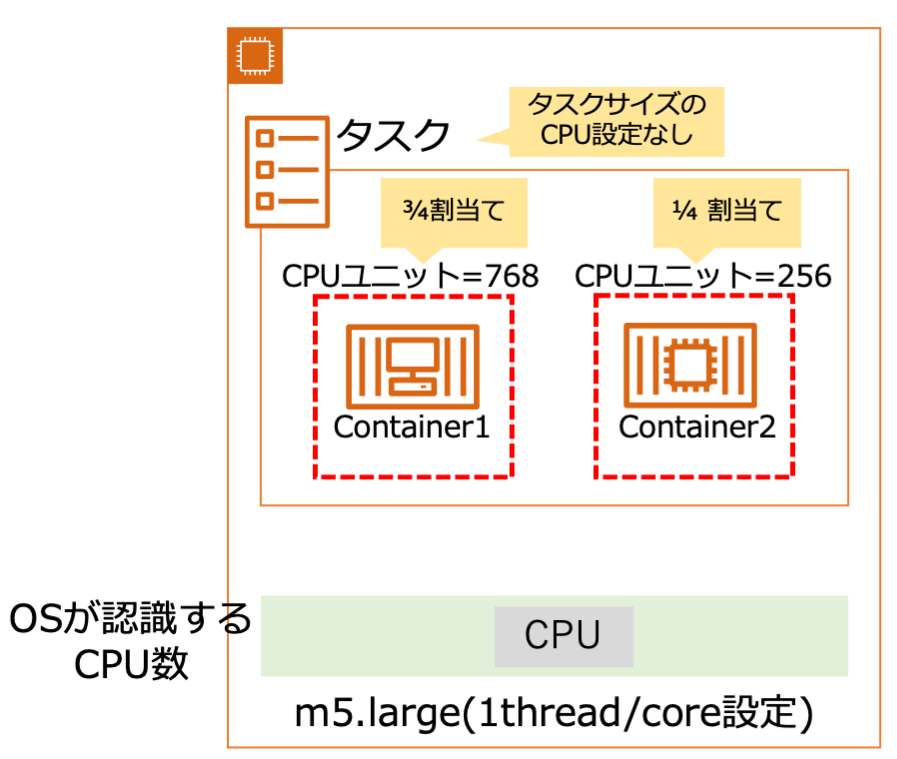
この状態で、ホストOSにsshでログインして、下記コマンドでそれぞれのコンテにCPU負荷を与えます。
docker exec -it <コンテナID> /bin/bash -c 'while true;do :; done;'
2つのコンテナにCPU負荷を欠けた状態で、ホストOS上でdocker container statsでコンテナのリソース利用状況を確認します。すると、container1がCPU利用率約 75%、container2がCPU利用率約 25%でCPUユニットの設定通りの制限がかかっていることが確認できました。

次に、この状態からContainer2の負荷をゼロにします(docker exec・・・のコマンドを、CTRL+Cで強制終了します)。すると、container1のCPU利用率が約100%になりました。

ここまでで、CPUユニット設定の割合でCPU配分が決まることと、CPUに空きがある場合はタスクはCPUユニットの設定以上のCPUリソースを利用可能なことが確認できました。
(1)ホストOSが2CPUの場合
では次に、m5.xlarge(1スレッド/core設定) x 1ノード構成でホストOSが2CPUの場合どのような挙動になるか確認します。タスク定義は、先ほどの物と同じです。
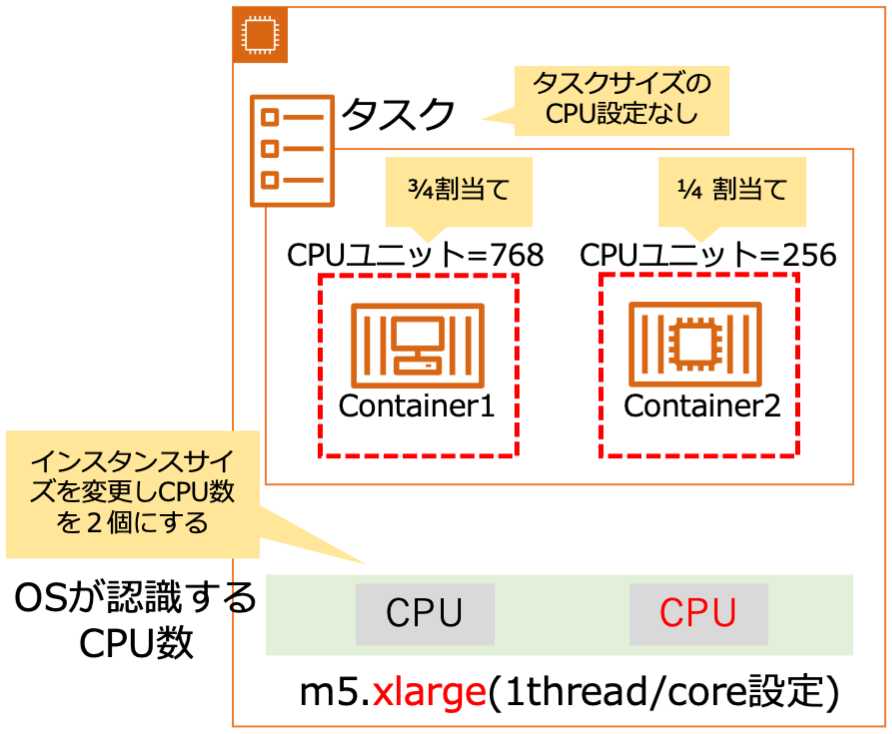
この状態でまず、container1にのみ負荷をかけてみます。CPUの利用状況は、先ほどと同様container1のみCPU 100%の状態になりました。

次にcontainer2にも負荷をかけます。この場合普通に想像すると、container1とcontainer2のCPU利用率の割合は3:1になることを予想すると思います。しかし実態は、なぜか2つのコンテナともCPU利用率が約100%になりました。

この事象を理解するには、まずそれぞれのコンテナ上のプロセスがホストOSのどのCPUで実行されているかを確認する必要があります。
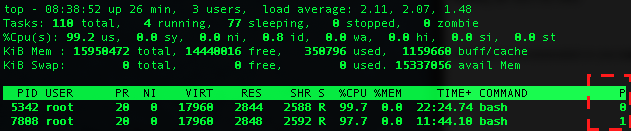
プロセスがどのCPUで実行されているかは、topコマンドで確認することができます。ただしデフォルトではこの情報は表示されないため、設定を変更する必要があります。具体的にはtopコマンドを実行し、fを押したあと、カーソルでP = Last Used Cpu (SMPに移動してdで表示するよう設定変更し、qで終了します。そうすると、右端にPという列が現れます。これはそのプロセスが最後に実行されたCPUのプロセッサ番号を表しています。
先ほどのcontainer1とcontainer2に負荷を掛けた状態で上記手順で、各プロセスが実行されているCPUを確認すると、0番と1番とありそれぞれのコンテナ上のプロセスが異なるCPUで実行されていることが確認できます。
ではなぜ実行CPUが異なることでCPUユニットの制限が適用されないのでしょうか。結論を言うとLinuxカーネルのcgroupの仕様ということになります。
Amazon ECSのコンテナのCPUユニットは、dockerのCPU Shares機能を利用してコンテナのCPUリソースの制限を実現しています。そしてdockerのCPU Shares機能は、Linuxの場合はlinuxカーネルのcgroupのcpu.sharesを利用してCPUリソースの制限を実現しています。このcgroupのcpu.shareは、複数のプロセスが CPU リソースを競い合う場合のみに有効な機能となります。*1
ここまでの内容を絵にまとめるとこんな感じです。
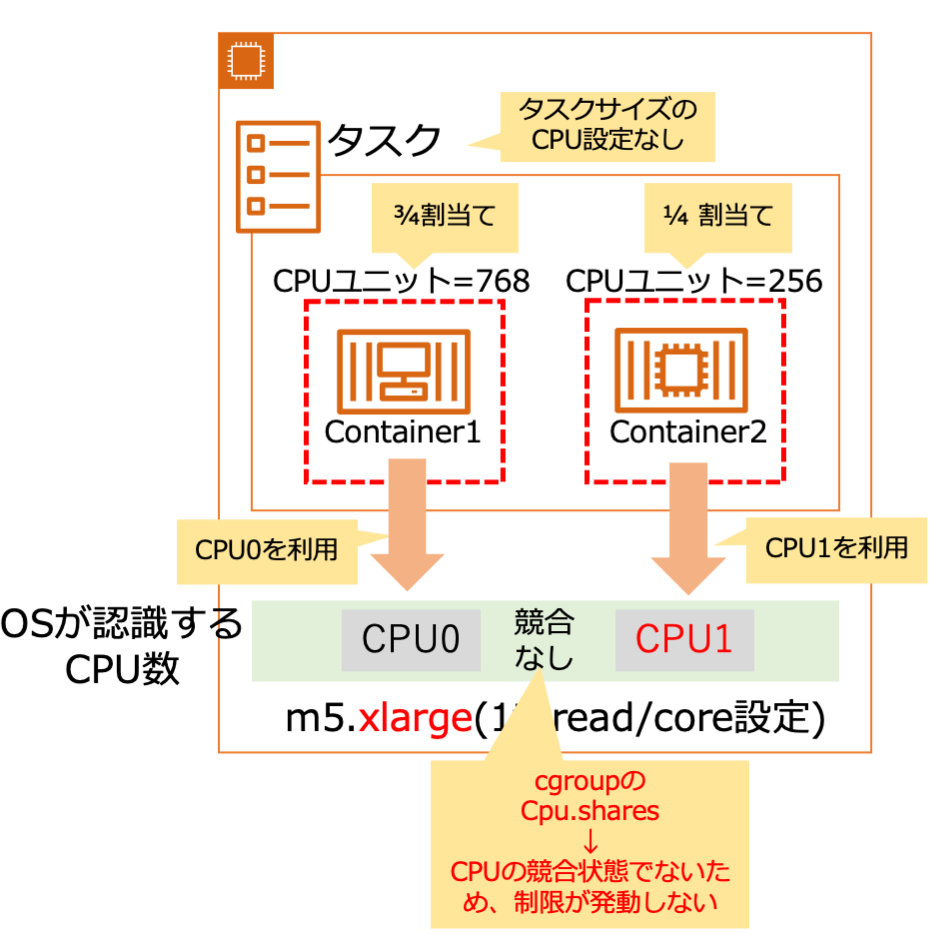
ではCPU競合状態になったら本当にCPUユニットの設定が発動するのか確認してみます。先ほどのタスク数を1個から2個に増やして4つのコンテナ全てにCPU負荷をかけてCPUの競合状態を発生させます。

すると予想通りCPUユニット設定が効果を発揮しそれぞれのタスクで、container1のCPU利用率は約75%、container2のCPU利用率は約25%になりました。

タスクサイズのCPU
次に、タスクサイズのCPUの挙動を実機で確認します。先ほどのCPUユニットの検証に利用したタスク定義に、タスクサイズのCPU設定を追加して以下の構成にします。
- タスク構成
- タスクサイズのcpu: 1024 (1CPUを割り当て)
- コンテナのCPUユニット
- container1: CPU Unit =
768 - container2: CPU Unit =
256
- container1: CPU Unit =
この構成で、CPUユニット検証で利用したm5.xlargeのEC2インスタンスでタスクを1つだけ起動します。構成を絵にすると以下の通りです。
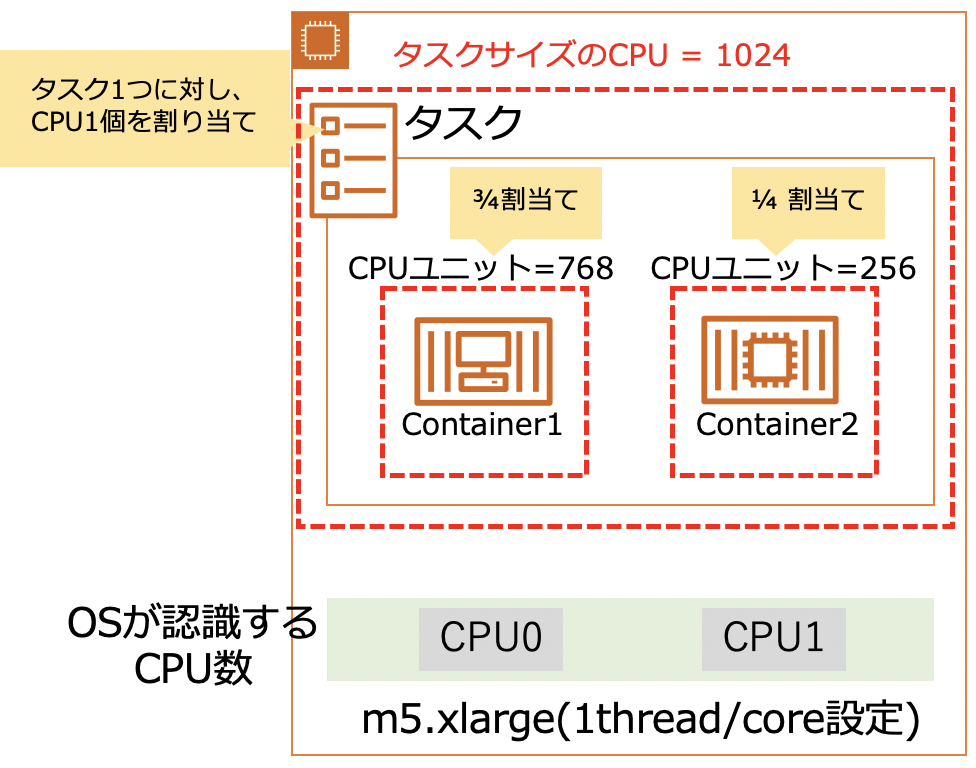
この状態で、2つのコンテナに対してCPU負荷を与えます。すると、先ほどのCPUユニット設定のみの場合はそれぞれのコンテナがCPUを100%利用しタスク全体では200%利用していましたが、今回はタスクサイズのcpu:
1024(=1CPUで制限)が入ったことで、それぞれのコンテナのCPU利用率は約50%にキャップされ、タスク全体で100%となりました。
この状態についてですが、まずCPUユニットは先どのCPUユニット設定のみの場合と同様、ホストOSが認識するCPU数2個に対してCPUを利用するプロセスも2個でCPUの競合が発生していない状態のため、CPUユニット設定によるCPUリソース制限は発動していない状態となります。その上でタスクサイズのCPU制限はハード制限でタスク全体で1CPU分のCPUリソースしか利用できない設定(cpu = 1024)のため、結果としてそれぞれのプロセスのCPU利用率が50%に制限されてしまった、という物になります。
ではCPU競合状態が発生した場合はどうなるのか次に確認します。cgroupの制御がかかっていないホストOS上でwhile true;do :; doneを実行してCPU競合状態を発生させます。状況を絵にすると以下の通りになります。

すると、予想通りですがCPU競合が発生しCPUユニットの設定が有効化されてcontainer1とcontainer2でCPU利用率が3:1の状態になりました。

タスクサイズのCPU設定について素潜りしてみる
すでにここまでで満腹感はありますが、もう一つ調べてみます。
コンテナのCPUユニットではdockerのCPU Shareを利用していることはAmazon ECSドキュメントに記載されていますが、タスクサイズのCPU設定については具体的な記載はありません。そこで実機のホストOSの中見てどんな風にタスクサイズの制限を実現しているか覗いてみます。
cgroupの構造を確認する
Linuxで動作するdockerでは、リソース制限をkernelのcgroupで実現しています。コンテナのCPUユニットは、話は端おりますが、dockerのCPU sharesの機能を利用しこの機能はcgroupのcpu.sharesで実現しています。ということからタスクサイズのCPUもcgroupの機能で実現しているだろうなというあたりが付きます。そこでまずタスクを起動したときのcgroupの構造を確認してみます。
ということで、タスクサイズのCPUの実機確認をした下記構成を使ってホストOS上でcgroup構成を確認します。
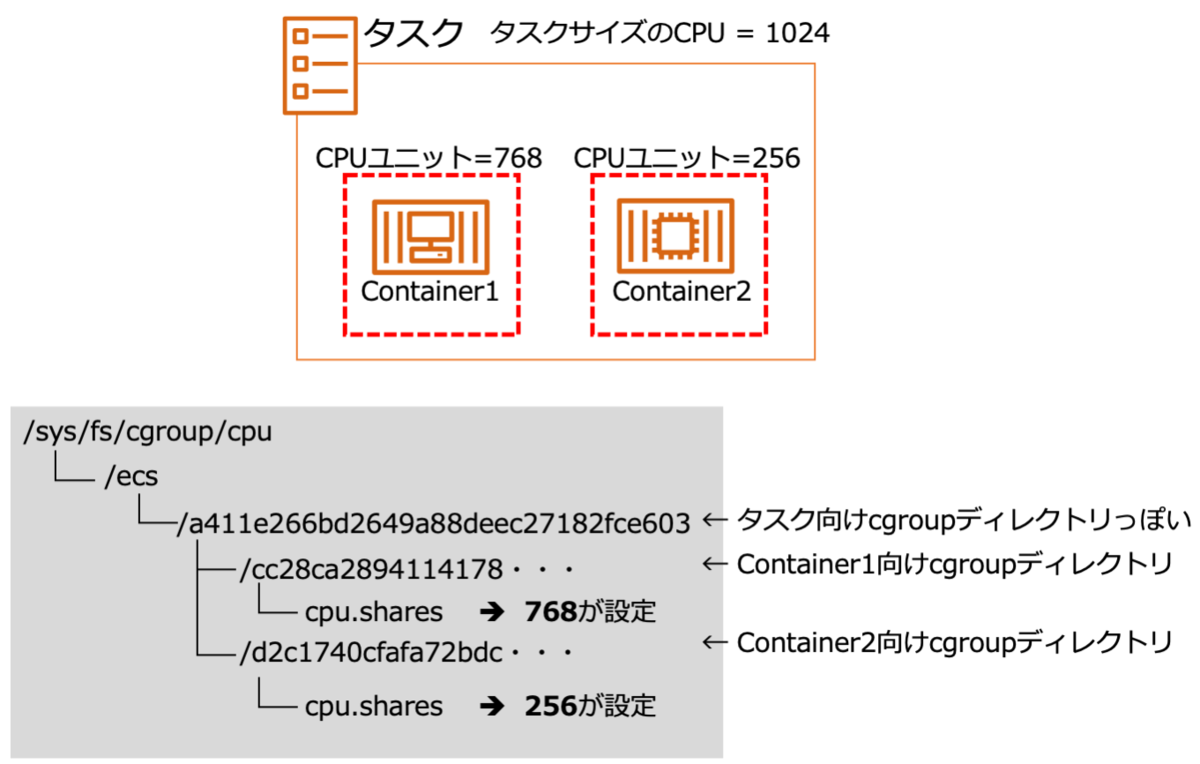
まずはdocker container inspectコマンドで、コンテナID、内部IDやcgroupの親ディレクトリなどを確認してみます。
ホストOS上でdockerコマンドで起動しているコンテナを確認します。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d2c1740cfafa 290054392706.dkr.ecr.ap-northeast-1.amazonaws.com/simple-httpserver:latest "docker-php-entrypoi…" About a minute ago Up About a minute (healthy) 0.0.0.0:32783->80/tcp ecs-cpuunit-and-tasksizecpu-1-container2-8afc9a86cdd6bac92500 cc28ca289411 290054392706.dkr.ecr.ap-northeast-1.amazonaws.com/simple-httpserver:latest "docker-php-entrypoi…" About a minute ago Up About a minute (healthy) 0.0.0.0:32782->80/tcp ecs-cpuunit-and-tasksizecpu-1-container1-d08d9fb3a4d6dbde8301 8851d081efe9 amazon/amazon-ecs-agent:latest "/agent" 3 hours ago Up 3 hours (healthy) ecs-agent
docker container inspect ><コンテナID>で、各コンテナの内部IDやcgroupのディレクトリを確認します。
$ sudo yum -y install jq $ CONTAINER_ID=cc28ca289411 $ docker container inspect ${CONTAINER_ID} | jq -r '.[] |{ Id:.Id, Name:.Name, CgroupParent:.HostConfig.CgroupParent, CpuShares:.HostConfig.CpuShares}' { "Id": "cc28ca2894114178ee023b549bfd29800f9ea311858d9c19b9bed38b308a1fbd", "Name": "/ecs-cpuunit-and-tasksizecpu-1-container1-d08d9fb3a4d6dbde8301", "CgroupParent": "/ecs/a411e266bd2649a88deec27182fce603", "CpuShares": 768 } $ CONTAINER_ID=d2c1740cfafa $ docker container inspect ${CONTAINER_ID} | jq -r '.[] |{ Id:.Id, Name:.Name, CgroupParent:.HostConfig.CgroupParent, CpuShares:.HostConfig.CpuShares}' { "Id": "d2c1740cfafa72bdc7b505dec468ce0bac02210222c3e977cce08a8f12394a3f", "Name": "/ecs-cpuunit-and-tasksizecpu-1-container2-8afc9a86cdd6bac92500", "CgroupParent": "/ecs/a411e266bd2649a88deec27182fce603", "CpuShares": 256 }
内容を表にまとめると以下の通りです。
| Container | CONTAINER ID | ID | CgroupParent | CpuShares |
|---|---|---|---|---|
| Container1 | cc28ca289411 | cc28ca2894114178ee023b549bfd29800f9ea311858d9c19b9bed38b308a1fbd | /ecs/a411e266bd2649a88deec27182fce603 | 768 |
| Container2 | d2c1740cfafa | d2c1740cfafa72bdc7b505dec468ce0bac02210222c3e977cce08a8f12394a3f | /ecs/a411e266bd2649a88deec27182fce603 | 256 |
この内容を踏まえてcgroupのCPUに関するリソース制限設定を確認してみます。cgroupのCPU制限設定は/sys/fs/cgroup/cpuディレクトリ配下で確認できます。またコンテナのCgroupParentから各コンテナの設定は、/sys/fs/cgroup/cpu/ecs/a411e266bd2649a88deec27182fce603配下であることがわかります。
$ cd /sys/fs/cgroup/cpu/ecs/a411e266bd2649a88deec27182fce603 $ ls -l 合計 0 drwxr-xr-x 2 root root 0 12月 13 11:05 cc28ca2894114178ee023b549bfd29800f9ea311858d9c19b9bed38b308a1fbd -rw-r--r-- 1 root root 0 12月 13 11:31 cgroup.clone_children -rw-r--r-- 1 root root 0 12月 13 11:31 cgroup.procs -rw-r--r-- 1 root root 0 12月 13 11:05 cpu.cfs_period_us -rw-r--r-- 1 root root 0 12月 13 11:05 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 12月 13 11:31 cpu.rt_period_us -rw-r--r-- 1 root root 0 12月 13 11:31 cpu.rt_runtime_us -rw-r--r-- 1 root root 0 12月 13 11:31 cpu.shares -r--r--r-- 1 root root 0 12月 13 11:31 cpu.stat -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.stat -rw-r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_all -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_percpu -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_percpu_sys -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_percpu_user -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_sys -r--r--r-- 1 root root 0 12月 13 11:31 cpuacct.usage_user drwxr-xr-x 2 root root 0 12月 13 11:05 d2c1740cfafa72bdc7b505dec468ce0bac02210222c3e977cce08a8f12394a3f -rw-r--r-- 1 root root 0 12月 13 11:31 notify_on_release -rw-r--r-- 1 root root 0 12月 13 11:31 tasks
ディレクトリのファイル一覧を見ると、container1/2のコンテナのID名のディレクトリがあることが確認できます。
では各コンテナのCPUユニット設定があるか確認してみます。
$ cat ./cc28ca2894114178ee023b549bfd29800f9ea311858d9c19b9bed38b308a1fbd/cpu.shares 768 $ cat ./d2c1740cfafa72bdc7b505dec468ce0bac02210222c3e977cce08a8f12394a3f/cpu.shares 256
Container1/2のCPUユニット設定が入っていることが確認できました。ここまでの内容を絵にまとめます。
タスクサイズのCPUはどのように制限を実現しているか
とここまで見ると、ecs/a411e266bd2649a88deec27182fce603にタスクサイズのCPU設定があるっぽいことが見えてきます。ということでこのディレクトリのパラメータ(ファイル)を眺めていくと、間の話は飛ばしますが、結果としてタスクサイズのCPUのリソース制限はcpu.cfs_period_usとcpu.cfs_quota_usで実現しているっぽいことがわかりました。
これらの設定は何かというと、以下の通りとなります。要は指定した期間で利用可能なCPU時間の制限で、CPUのハード制限の設定になります。詳しくはこちらのカーネルのドキュメントを参照下さい。
今回の環境のcgroupのCPU関連の設定を表にまとめると以下の通りになりました。
| 項目 | cpu.cfs_period_us | cpu.cfs_quota_us | cpu.shares |
|---|---|---|---|
| タスク | 100000 | 100000 | 1024 |
| Container1 | 100000 | -1 | 768 |
| Container2 | 100000 | -1 | 256 |
Container1/2は、cpu.cfs_quota_us = -1とありますが、これはContainer1/2単位ではcpu.cfs_quota_usによるCPUリソースのハード制限は無効化されているということになります。
一方でタスクは、 cpu.cfs_period_us = 100000(1秒)、cpu.cfs_quota_us = 100000(1秒)とあり、これはタスクは1秒間にCPUリソースを1秒分利用できる = CPU1個分のリソースが割り当てられているということになります。
ここまでの実機の挙動確認から、タスクサイズのCPU設定によるCPUリソース制限は、cgroupのcpu.cfs_period_us とcpu.cfs_quota_usで実現していそうだということまでが整理できました。
タスクサイズのCPUのcgroup設定は誰が行っているのか
これが最後です。ではタスクサイズのCPU設定のcpu.cfs_period_us とcpu.cfs_quota_usは誰が設定しているのでしょうか?
ここまで来ればおそらくAmazon ECS Agentが設定しているだろうということはあたりがつきます。そこで、Amazon ECS Agentのプロセスのステムコールトレースを取得して確認してみます。
sudo yum -y install strace ps -ef|grep -v grep |grep '/sbin/docker-init -- /agent' root 4261 4232 0 08:12 ? 00:00:00 /sbin/docker-init -- /agent sudo strace -f -tt -p 4261 -o ecs_agent_strace.log
で、ログを見ると cpu.cfs_period_usとcpu.cfs_quota_usのファイルへの書き込みをしていることが見て取れます。
<前略>
#ディレクトリの作成
23434 11:05:13.722263 mkdirat(AT_FDCWD, "/sys/fs/cgroup/systemd/ecs/a411e266bd2649a88deec27182fce603", 0755) = 0
<中略>
#cpu.cfs_period_usへの書き込み
23434 11:05:13.724464 openat(AT_FDCWD, "/sys/fs/cgroup/cpu/ecs/a411e266bd2649a88deec27182fce603/cpu.cfs_period_us", O_WRONLY|O_CREAT|O_TRUNC|O_CLOEXEC, 000) = 27
23434 11:05:13.724487 epoll_ctl(4, EPOLL_CTL_ADD, 27, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=3911208272, u64=140054204796240}}) = 0
23434 11:05:13.724505 fcntl(27, F_GETFL) = 0x8001 (flags O_WRONLY|O_LARGEFILE)
23434 11:05:13.724519 fcntl(27, F_SETFL, O_WRONLY|O_NONBLOCK|O_LARGEFILE) = 0
23434 11:05:13.724535 write(27, "100000", 6) = 6
23434 11:05:13.724562 epoll_ctl(4, EPOLL_CTL_DEL, 27, 0xc00050d7a4) = 0
23434 11:05:13.724577 close(27)
<中略>
#cpu.cfs_quota_usへの書き込み
23434 11:05:13.724594 openat(AT_FDCWD, "/sys/fs/cgroup/cpu/ecs/a411e266bd2649a88deec27182fce603/cpu.cfs_quota_us", O_WRONLY|O_CREAT|O_TRUNC|O_CLOEXEC, 000) = 27
23434 11:05:13.724616 epoll_ctl(4, EPOLL_CTL_ADD, 27, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=3911208272, u64=140054204796240}}) = 0
23434 11:05:13.724633 fcntl(27, F_GETFL) = 0x8001 (flags O_WRONLY|O_LARGEFILE)
23434 11:05:13.724647 fcntl(27, F_SETFL, O_WRONLY|O_NONBLOCK|O_LARGEFILE) = 0
23434 11:05:13.724662 write(27, "100000", 6) = 6
23434 11:05:13.724683 epoll_ctl(4, EPOLL_CTL_DEL, 27, 0xc00050d7a4) = 0
23434 11:05:13.724698 close(27)
まとめ
本記事では、Amazon ECS タスク定義の"タスクサイズのCPU"と”コンテナのCPUユニット”の違いをドキュメントと実機の挙動確認から調べてみました。
調査結果としては、以下の通りになります。
- コンテナのCPUユニットは、
- 各コンテナに対するCPU制限で、各コンテナ合計値に対する設定値の割合で利用可能なCPUリソースが決まる
- ECSはdockerのCPU Sharesを利用し実現しており、dockerはLinuxの場合はcgroupの
cpu.sharesで機能を実現している - cgroupの
cpu.shares仕様で、CPUの競合が発生していない時はコンテナのCPUユニットによる制限は発動しない
- タスクサイズのCPUは、
- 単一のタスクが対象となり、設定値はハードリミットになる
- 実機確認の限りでは、Linuxではcgroupの
cpu.cfs_period_usとcpu.cfs_quota_usで機能を実現しているように見える
最後に
私は普段は、AWS Professional ServicesとしてAWS クラウドを使用して期待するビジネス上の成果を実現するようお客様を支援しています。
Professional Servicesには、私みたいな人以外に、ML、Bigdata、セキュリティ、アジャイル、UI/UXのデザインなど各分野のスペシャリストが揃っているエキサイティングなチームです。
興味がある方はこちらの採用のページをご確認ください。
aws.amazon.com