AWS CodeCommitを使ってみた
1.AWS CodeCommitとは?
「AWS CodeCommit は、プライベート Git リポジトリをホストする、安全で高度にスケーラブルなマネージド型のソース管理サービス」です。平たく言えば、「簡単にプライベートなGitリポジトリが利用できるAWSサービス」です。
料金は、5ユーザまで、ストレージ50GB/月まで、10,000Gitリクエスト/月まで、無料で利用できます。
詳細は下記AWSのCodeCommitの概要を参照して下さい。
2.使ってみる

2.2 gitアクセス用のIAMアカウントを作ってみる
設定内容
2.3 gitコマンドでcloneしてみる
gitの初期設定
PCにgitがインストールされてない場合は、gitをインストールします。
インストール後に、gitの初期設定として、(1)メールアドレス、(2)名前、(3)push時のモードを指定して、最後に設定内容を確認します。
$ git config --global user.email "xxxxxxx@gmail.com" $ git config --global user.name "xxxxxxxx" $ git config --global push.default simple $ git config --global -l
CodeCommitと接続しリポジトリをcloneする
- AWSコンソールで、CodeCommitの対象レポジトリに移動し「クローンURL」の「https」のURLをコピーする
- コンソールを開き、下記コマンドでcloneする
- 実行するとユーザ名とパスワードを聞かれるので、控えた「HTTPS Git 認証情報」を入力する
- "git branch"はcloneされたことを示すためのコマンドで必須ではない
$ git clone <https://リポジトリcloneURL> Cloning into 'リポジトリ名... Username for 'https://git-codecommit.ap-northeast-1.amazonaws.com': XXXXXXXX <==控えたユーザ名を入力 Password for 'https://XXXXXXXX@git-codecommit.ap-northeast-1.amazonaws.com': XXXXX <== 控えたパスワードを入力 $ cd <リポジトリ名称> $ git branch -a * master remotes/origin/HEAD -> origin/master remotes/origin/master
3.gitコマンドでの、HTTPS Git認証情報の扱いについて
cloneする時に入力したHTTPS接続ときのユーザ名とパスワードは、gitのcredential.helper機能を使い管理することができます。
管理モードは以下の5つです。*5
- 管理しない
- メモリ上に一時キャッシュする: cache
- テキストファイルで保存する: store
- (Macのみ)Macのキーチェーンを利用する: osxkeychain
- (Winのみ)Windowsの管理機能(Windows Credential Store)を利用する: wincred
プラットホームごとの確認はしてないですが、少なくともMacはosxkeychainがデフォルトのようですので、特に意識しなくても大丈夫そうです。(git公式ページのgit-osx-installerからセットアップした場合)
*1:https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/setting-up.html
*2:https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/best-practices.html#bp-use-aws-defined-policies
*3:IAMSelfManageServiceSpecificCredentialsは、自分のIAMの認証設定の参照/変更用ポリシーのようです
*4:IAMReadOnlyAccessは、IAM情報の参照用ポリシーのようです
clock_gettime()で負荷をかけたEC2をNetflix FlameScopeでのぞいてみた
- はじめに
- セットアップ手順①(MacにFlameScopeをセットアップする)
- セットアップ手順②(測定対象のLinuxにperfをインストールする)
- テスト用にワークロードを準備する
- linuxで測定する
- FlameScopeで分析する
- FladeScopeでドリルダウン分析してみる
- (蛇足)/sysからt2.microのクロックソースを確認
- 参考
はじめに
ablogさんのこちらの記事=>Netflix のオープンソース可視化ツール FlameScope を使ってみた - ablogの二番煎じですが、FlameScopeを教えてもらったので使ってみました。
FlameScopeとは
Netflixのパフォーマンスエンジニアチームがリリースしたperfで取得した性能情報をブラウザでビジュアルに分析できるツールです。詳しくはNetflixのblogやablogの記事を参照してください。
セットアップ手順①(MacにFlameScopeをセットアップする)
基本は、GitHub - Netflix/flamescope: FlameScope is a visualization tool for exploring different time ranges as Flame Graphs.に書いてあります。
基本FrameScopeのgithubに記載されている手順でいけますが、私のMacは前提のツールが何も入っていなかったのでもう一手間かかりました。
(1)前提パッケージのセットアップ
(a)gitコマンドのセットアップ
下のqiita記事を参考にgitコマンドをインストールしてください。
gitはAppleの認証がなくインストールでエラーになる場合がありますが、その場合はエラーになった後に"システム環境設定"->"セキュリティーとプライバシー"からインストールを実行してください。
(b)pipコマンドのセットアップ
- Xcodeのセットアップ
pipのセットアップの中でccコマンドでビルドしているようなので、 ccコマンドを使えるようにするためにMacの開発環境であるXcodeを先にインストールします。
インストールは、”AppStore”から”Xcode”で検索してインストールします。
- pipインストール
こちらの記事を参考にpipをインストールします。
手順は、
(i)get-pip.pyダウンロード
https://pip.pypa.io/en/stable/installing/ から、get-pip.pyファイルをダウンロードする。
(ii)pipインストール
python get-pip.py --user export PATH="$HOME/Library/Python/2.7/bin:$PATH" echo 'export PATH="$HOME/Library/Python/2.7/bin:$PATH"' >> ~/.bash_profile
(iii)既存パッケージのアップデート
pip freeze --local | grep -v '^\-e' | cut -d = -f 1 | xargs pip install -U --user
(2)FlameScopeのセットアップ
FlameScopeのgithubにあるインストール手順をそのまま実行します。
cd ~/ git clone https://github.com/Netflix/flamescope cd flamescope pip install -r requirements.txt
セットアップ手順②(測定対象のLinuxにperfをインストールする)
今回はAWSのEC2(t2.micro)のAmazon Linux 2を利用しています。FlameScopeのgithubの説明通りです。
sudo yum install perf
テスト用にワークロードを準備する
負荷がかかってない状態で測定しても何も面白くないので、何からかの負荷がけをします。負荷は何でもよいのですが、今回は時刻取得を約3355万回(2^25)繰り返す負荷ツールを作りました。clock_gettime()を呼び出す部分をアセンブラで書いていますが、ただの趣味です。こんなキモいことしなくても大丈夫です。
/* work.c */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #define _GNU_SOURCE #include <unistd.h> #include <sys/syscall.h> #include <sys/types.h> #define MAX 1LU << 25 /* MAX = 2^25 */ int main() { struct timespec tp; char *mes; int ret; unsigned long loop; for(loop=0; loop<MAX; loop++){ asm volatile( /* call clocl_gettime api */ "mov %3, %%rsi;" "mov %2, %%rdi;" "mov %1, %%rax;" "syscall;" "mov %%eax, %%eax;" "mov %%eax, %0;" : "=&m"(ret) : "g"(SYS_clock_gettime), "g"(CLOCK_REALTIME), "g"(&tp) : ); } printf("execute %lu times.\n",loop); return ret; }
このコードをgccでビルドします。(デフォルトではgccが入っていないのでyumでインストールしてビルドします)
sudo yum install gcc gcc work.c
linuxで測定する
負荷は、作成したツールを4回、10秒のインターバルを置いて実行するようにしました。
sleep 15;for i in `seq 1 4`;do time ./a.out;sleep 10;done
それと同時に、別のターミナルでperfでプロファイルの収集を開始します(秒間49回で、120秒間測定)。
sudo perf record -F 49 -a -g -- sleep 120
- -F: 49:秒間49回データ収集を行う。(秒間50回が分析にちょうど良い分解能度で、でも50回だと周期性が出てハマってしまう(lock-step)可能性があるから、周期性が出ないよう半端な49回にするということ?)
- -a: 全てのCPUコアを対象にシステムワイドでプロフィル収集する
- -g: call-graphを有効化する
perfのデータ収集が完了したらレポートを出力しgzip圧縮する
sudo perf script -f --header > stacks.log gzip stacks.log
FlameScopeで分析する
- 収集し、圧縮したstacks.log.gzファイルをMacに転送します。
- 転送したstacks.log.gzを”flamescope/example”に移動します*1
- FlameScopeを起動します。
cd ~/flamescope python run.py
- ブラウザで、http://127.0.0.1:5000/にアクセスする。
- stack.log.gzを選択する
- 右上のRawsから、perfの分解能度に合わせた行数を選択する(49を選択)
すると、こんな感じで見えます。
赤いところがイベントが多数出ている→負荷がかかっている、場所になります。

FladeScopeでドリルダウン分析してみる
上記の赤い濃淡の図の中から気になる部分があったら、その部分をFlameGraphでドリルダウン分析します。例えば最初の赤い時間帯の開始タイミングと終了タイミングで2回クリックするとその範囲が選択され、下記のFlameGraphで詳細分析することができます。

t2.microのクロックソース
上記の図を見ると、
- a.outのmain()から、システムコール呼び出し(entry_SYSCALL_64_after_hwframe)からdo_syscall_64()が呼ばれ、
- そこから、sys_clock_gettime()が呼ばれて以下実行され、
- 最終的に、pvclock_clocksource_read()が呼び出されているのがわかります。
なおpvclock_clocksource_read()のコードがどこにあるかカーネルを別途見ると、arch/x86/kernel/pvclock.cにあるようです*2。pvclockという名前からparavirtualのclocksourceであることが推測でき、コードタイトルにも”paravirtual clock -- common code used by kvm/xen”とあるので、t2.microのクロックソースコードはパラバーチャルであることが裏付けられます。( ちなみに、lvm/xenで共通化されているんですね)
処理負荷が高いポイント
clock_gettimeを回して負荷をかけているので当然、処理時間の大半がシステムコール処理にリソースを費やされています。実際FlameGraphを見るとdo_syscall_64が処理時間全体の7割弱を占めているのがわかります。ただ、実際に時刻取得処理を行うdo_clock_gettime()は、do_syscall_64()の半分の処理時間割合であることから、システムコールによるユーザ空間からカーネル空間へのコンテキストスイッチは相当のオーバーヘッドがあることが伺えます。

(蛇足)/sysからt2.microのクロックソースを確認
蛇足ですが最後に、実機の/sysからカレントのクロックソースを確認します。
- (1)利用可能なソースコード一覧
kernel的には、xen, tsc, hpet, acpi_pmの4つが選択可能に見えます。
$ cat /sys/devices/system/clocksource/clocksource0/available_clocksource xen tsc hpet acpi_pm
- (2)カレントのクロックソース
xenですね。
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource xen
参考
- FlameScope
- perf
- gitコマンド
- pipコマンド
subprocessでコマンド実行し、例外処理でOSErrorとコマンドのリターンコードの非ゼロ(エラー)をそれぞれハンドルするサンプル
サンプルコード
私自身の勉強用です。コードは、python2.7ベースです。
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys import subprocess def call_subprocess(cmd): try: r = subprocess.check_output( cmd, stderr=subprocess.STDOUT ) sys.stdout.write(r+'\n') except OSError as e: sys.stderr.write('file ='+str(e.filename)+'\n') sys.stderr.write('errno='+str(e.errno)+'\n') sys.stderr.write('error='+e.strerror+'\n') return(1) except subprocess.CalledProcessError as e: sys.stderr.write('ret='+str(e.returncode)+'\n') sys.stderr.write('cmd='+str(e.cmd)+'\n') sys.stderr.write('output='+e.output+'\n') return(1) return(0) #test1 a command is success print('<<<<<test1>>>> a command is success.' ) cmd = [ 'echo','hoge hoge' ] ret = call_subprocess(cmd) print('function return = '+str(ret) ) #test2 command is failed print('<<<<<test2>>>> a command is failed.' ) cmd = [ 'cat','hoge hoge' ] ret = call_subprocess(cmd) print('function return = '+str(ret) ) #test3 OS error print('<<<<<test3>>>> OS Error.' ) cmd = [ 'NonexistingFile','hoge hoge' ] ret = call_subprocess(cmd) print('function return = '+str(ret) )
プロセスのVSZ,RSSとfree,meminfoの関係を実機で確認する
1.はじめに
1-1.この記事の要旨
psコマンドのVSZ(仮想メモリ)、RSS(物理メモリ)の挙動について質問を受けたので、簡単な検証プログラムを作ってmalloc/freeのメモリ確保/解放や、データの読み込み・書き込みとVSZ/RSSの関係性及び、freeコマンドとmeminfo情報でシステムワイドなメモリの挙動について確認しました。
検証結果から以下の挙動を実機で確認しました。
- 検証結果



1-2.(予習)メモリに関する指標とlinuxのメモリ挙動について
この記事に出てくる、メモリに関する指標値の説明です。
- psコマンド
- freeコマンド
- meminfo
- MemFree : 未使用のメモリ量です。freeコマンドの"free値"の元になっています。
- AnonymousPage(無名ページ): swapアウト対象となるページ。ざっくりというとプロセスが普通使っているメモリ。
- FilePage(ファイルページ):メモリ不足時、解放されるページ。ざっくりいうとファイルキャッシュのメモリ。
- active: AnonymousPage/FilePageのうち、比較的最近アクセス(read or write)されたページ。swapアウトや解放されないページではない。*3
- inactive:AnonymousPage/FilePageのうち、しばらくアクセスされていないページ
2.検証環境と検証方法
2-2.検証方法
下記動作を行う検証プログラムを作成し実行します。なお検証をわかりやすくするために、動作の間に10秒のsleepをかけています。
- malloc()で512MBのメモリを確保する
- 確保した512MBのメモリ領域を20秒かけてreadする(1秒間隔で1/20のサイズずつ20回readする)
- 同じ領域に、20秒かけてデータを書き込む
- もう一度同じ領域を、20秒かけて読み込む
- free()で確保したメモリを解放する
プログラムは以下のリンク先にありますので、これをgccで"gcc verifying_memory.c"とかしてビルドします。
Verifying on Memory behavior · GitHub
ちなみにglibcのmalloc()は、サイズが128kb(変更可)より大きい場合はmmap()取得になります。*4
ですので512MB確保している今回の検証は、必ずmmap()になります。
2-3.測定方法
(1)psコマンドによるVSZ,RSS情報の取得
簡単ですが、下記のワンライナーコマンドで1秒間隔で取得しました。(検証プログラムのファイル名は、"a.out")
echo -n 'DATE '; ps -aux|head -n 1;while true;do printf '%s ' "`env LANG=C date '+%X.%N'`";env LANG=C ps -aux|grep -e a.out|grep -v grep;sleep 1;done
(2)freeコマンドとmeminfo情報の取得
こちらの記事のシェルで取得しました。
freeコマンドとmeminfoを取得してCSV形式で保存するシェルスクリプト - のぴぴのメモ
3.結果
3-1.全体の結果
psコマンドのVSZ/RSS、freeコマンド、meminfoの推移を並べると以下のようになります。
3-2.プロセスのVSZ/RSS挙動
ポイント① malloc()した時の挙動→VSZのみ増加
malloc()で512MBを取得したタイミングで、VSZが増加しているのがわかると思います。
一方RSSは、malloc()しただけでは増えてなく、このタイミングでは物理メモリの割り当てが発生していないことがわかります。(次のfreeコマンドやmeminfoの結果と照らし合わせて見るとよりわかりやすいです。)
ポイント② 1回目のデータread時→RSSは増えない
malloc()した後、そのデータをreadしても、物理メモリの割り当ては発生しません。そのため、RSSも増加しません。
実はプロセスがカーネルからメモリ確保したタイミングでは、確保した仮想メモリのページは、”zero page”という1ページがすべて0データで埋められた特殊なページにマッピングされており、データをreadした時は、その"zero page"の値を参照するためです。*5
ポイント③ データwrite→RSSが増加する
データのwriteが発生した時点で、RSSが増加していることがわかります。つまりデータへのwriteのタイミングで、そのwriteした仮想メモリのページに、晴れて物理メモリが割り当てられたということです。
これはカーネルのCOW(Copy-On-Write)という手法で、mallocなどでメモリを確保したタイミングでは実際には物理メモリの割り当てはせず、必要になったタイミングで初めて物理メモリを割り当ているからです。*6
もう少し詳しく書くと、先ほど説明したzero pageは書き込み禁止設定がされており、そこにデータを書こうとするとページフォルトが発生します。ページフォルトが発生すると、ページフォルトの割り込み処理の中にあるCOWの実装で、zero pageの内容を新しいページにコピーしして、そのページを改めて仮想ページとマッピングします。その時にRSSが+1ページ加算されます。
3-3.システムワイドな挙動(freeコマンド/meminfo)
ポイント① malloc()した時の挙動→usedもAnonymousPageも増えない
malloc()した時には、RSSが増えてない、つまり物理メモリへのマッピングがされていないため、freeコマンドやmeminfoでシステムワイドで見た物理メモリの利用状況でも、変化はありません。
ポイント②1回目のデータread時→変化しない。
同じですね。物理メモリの割り当てが発生しないため、freeコマンドやmeminfoも変化はありません。
ポイント③ データwrite→used上昇、AnonymousPage上昇
Writeするタイミングで、物理メモリの割り当てが発生するため、Usedが上昇します。meminfoでさらに詳しく見るとその上昇しているところが、AnonymousPage(無名ページ)であることが確認できます。
4.参考ページ
*1:kernelは、”MemTotal - MemFree - AnonymousePage(Active/InActive) - FilePage(Active/InActive) - Unevictable+Mlocked”で算出しています。
*2:"total - free - buffers - cache"で計算された値になります。RHEL6まではbuffer/cacheを含んでいましたが、RHEL7からはbuffer/cacheが含まれない値になりました。
*3:/proc/meminfo の Inactive は利用可能なメモリ領域ではない - ablog
*4:glibcのmalloc()は、指定するメモリサイズが小さい場合(閾値はMMAP_THRESHOLDで設定されており、デフォルトは128kb)は、Java vmのヒープのように、カーネルから取得済みで未使用となったメモリ領域をglibc内で保持して再利用する実装があるため、malloc()により必ずしもVSZが増加するとは限りません。詳しくはmalloc()のmanの注意(NOTES)を参照。
*5:memory management - Linux kernel: Role of zero page allocation at paging_init time - Stack Overflow
Linuxのclock_gettime()でナノ秒の時刻取得をするCのサンプル
1.はじめに
clock_gettime()で時刻を取得し時刻をナノ秒で表示するサンプルです。時刻取得といえばgettimeofday()ですが、POSIXではgettimeofdayは廃止予定で、clock_gettime()の利用を推奨しているので、こちらを利用しています。
2.コードと実行例
(1)コード
#include <stdio.h> #include <time.h> int main(){ struct timespec ts; struct tm tm; // 時刻の取得 clock_gettime(CLOCK_REALTIME, &ts); //時刻の取得 localtime_r( &ts.tv_sec, &tm); //取得時刻をローカル時間に変換 // 出力 printf("tv_sec=%ld tv_nsec=%ld\n",ts.tv_sec,ts.tv_nsec); printf("%d/%02d/%02d %02d:%02d:%02d.%09ld\n", tm.tm_year+1900, tm.tm_mon+1, tm.tm_mday, tm.tm_hour, tm.tm_min, tm.tm_sec, ts.tv_nsec); return(0); }
3.説明
(1)clock_gettime(CLOCK_REALTIME, &ts)
時刻を取得します。最初の引数は取得する時刻の種類を指定しており、"CLOCK_REALTIME"はシステム全体で一意な精度の高い実時間情報を取得します。取得した情報は、2つ目の引数のtimespec構造体に格納されます。
struct timespec {
time_t tv_sec; ==> 1970年1月1日からの秒数が格納されます。
long tv_nsec; ==> 秒未満の時刻(ナノ秒)で格納されます。
};
(2)localtime_r( &ts.tv_sec, &tm)
取得した時刻のうち、tv_sec(1970年1月1日からの秒数)を年/月/日/時/分/秒に変換し、tm構造体に格納します。
localtime_r()は、localtime()と同じ処理になりますが、localtime()はスレッドセーフでなく、localtime_r()はスレッドセーフな実装になります。スレッドセーフでないlocaltime()はマルチスレッド環境で利用すると想定外の挙動を起こす可能性があるため、今回のサンプルではマルチスレッドでも使えるように、スレッドセーフなlocaltime_r()を利用しています。
(3)printfで出力
localtime_rで変換した時刻情報を、printf()で出力します。秒未満は、timespecのtv_nsecに格納されているので、tv_nsecを使って秒の小数点以下の値を出力しています。

最小構成でmanがない場合の対処方法->man-pagesをインストール
結論
タイトル通りですが、備忘録です。
CentOSやRHELで最小構成でインストールした場合、最小限のコマンドマニュアルしかなくて、man(2)、man(3)・・・は、入っていないのですね。
結論から言うと、そんな時は"man-pages"(日本語も必要な場合は、man-pages-jaを追加で)のパッケージをインストールするとman見れるようになります。
yum install man-pages man-pages-ja
お世話になったページ
おそらく同じ悩みをした人がいるとググってヒットした、こちらのページを参考にしました。
hyperneetprogrammer.hatenablog.com
記事は苦労が伺える内容になっていますが、結論だけ使わせていただきました。すみません。先人の方の努力に感謝します。
リンク先記事は、CentOS6.4ですが、RHEL7でも問題なくmanが使えるようになりました。
freeコマンドとmeminfoを取得してCSV形式で保存するシェルスクリプト
はじめに
昔作った/proc/meminfoを取得時刻情報取得スクリプトを改造して作った、freeコマンド+/proc/meminfoを取得して、CSV形式で出力するシェルスクリプトです。
nopipi.hatenablog.com
ツール説明
シェルスクリプト
下記URL先のgistにあります。
collect memory information(free command and /proc/meminfo), and output in CSV format. · GitHub
使い方
- シェルのファイルを配置して、"chmod +x collect_mem.sh"で実行権限を付与する。
- 実行する。(カレントディレクトリに、"meminfo.YYYYMMDDHHMMSS"形式で3秒間隔でデータが出力されます)
- 終了したい場合は、”Ctrl+c”で終了する。
出力結果
CSV形式で以下の情報がファイルに出力されます。
- 取得日と時刻
- freeコマンド 2行目(Mem:)の各情報
- freeコマンド 3行目(Swap:)の各情報
- /proc/meminfo情報
"DATE","TIME","free-mem-total(kb)","free-mem-used(kb)","free-mem-free(kb)","free-mem-share(kb)","free-mem-buff/cache(kb)","available(kb)","free-swap-total(kb)","free-swap-used(kb)","free-swap-free(kb)","MemTotal:(kB)","MemFree:(kB)","MemAvailable:(kB)","Buffers:(kB)","Cached:(kB)","SwapCached:(kB)","Active:(kB)","Inactive:(kB)","Active(anon):(kB)","Inactive(anon):(kB)","Active(file):(kB)","Inactive(file):(kB)","Unevictable:(kB)","Mlocked:(kB)","SwapTotal:(kB)","SwapFree:(kB)","Dirty:(kB)","Writeback:(kB)","AnonPages:(kB)","Mapped:(kB)","Shmem:(kB)","Slab:(kB)","SReclaimable:(kB)","SUnreclaim:(kB)","KernelStack:(kB)","PageTables:(kB)","NFS_Unstable:(kB)","Bounce:(kB)","WritebackTmp:(kB)","CommitLimit:(kB)","Committed_AS:(kB)","VmallocTotal:(kB)","VmallocUsed:(kB)","VmallocChunk:(kB)","HardwareCorrupted:(kB)","AnonHugePages:(kB)","HugePages_Total:()","HugePages_Free:()","HugePages_Rsvd:()","HugePages_Surp:()","Hugepagesize:(kB)","DirectMap4k:(kB)","DirectMap2M:(kB)" 2017/09/27, 03:46:11,1883560,386348,792416,70516,704796,1237452,839676,0,839676,1883560,792680,1237716,5652,618276,0,313016,390848,80848,69604,232168,321244,0,0,839676,839676,0,0,79948,23984,70516,80868,45604,35264,1744,4952,0,0,0,1650384,365624,34359738367,7444,34359728128,0,6144,128,128,0,0,2048,44992,2052096 2017/09/27, 03:46:14,1883560,386144,792616,70516,704800,1237656,839676,0,839676,1883560,792680,1237720,5652,618280,0,313044,390848,80872,69604,232172,321244,0,0,839676,839676,4,0,79956,23984,70516,80868,45604,35264,1808,4924,0,0,0,1650384,365624,34359738367,7444,34359728128,0,6144,128,128,0,0,2048,44992,2052096
*補足
HugePage周りの挙動を確認するための情報収集用にこしらえたものです。
"LB + Web x 2 + RDB"マルチAZ”でWordPressをインストールするCloudFormation
はじめに
前にAWSさんの体験ハンズオンで経験した"LB + Web x 2 + DB x 2"環境構築して、そこに動作確認としてWordPressをインストールして動かすところまでの手順を、CloudFormationを使って自動化して見ました。WordPressのインストールは、CloudFormationのcfn-init ヘルパースクリプトを使っています。
構成概要

CloudFormationコード
SRPM展開&Gun global解析&squashfs化する自作ツールの説明
1.ツールができること
"srpm2html.py"は、SRPMソースコードを展開、Gnu global処理、その他諸々を自動化する自作ツールです。
具体的には、このツールを使うと以下の一連の作業をサボることができます。
- SRPMパッケージを所定のウェブサイトからダウンロードして
- SRPMをインストールして
- SRPMからソースコードを展開(rpmbuild -bpコマンド実行)して
- Gnu globalでコードをタギング解析してhtml化して
- globalで作成したhtmlファイルと、ソースコードの2つをそれぞれsquashfs化して
- squashfsのマウント先ディレクトリを作成して
- "/etc/fstab"に作成したsquashfsファイルのマウントエントリーを追加して
- squashfsをマウントしてくれる
コードはgithub(gist)に登録してあります。
- GitHub(gist)登録先: srpm2html.py
- ライセンス:Apache License, Version 2.0
2.インストール方法
2.1 前提環境
Linuxであれば多分動くと思います。(私は、CentOS6,AmazonLinux上で利用しています)
2.2 前提パッケージ
この自作ツールを実行するためには以下のrpmパッケージが必要です。*1*2
sudo yum install rpm-build squashfs-tools gcc make ncurses-devel
2.3 Gnu Globalのインストール
Gnu globalはソースコードをダウンロードしてmakeします。
wget http://tamacom.com/global/global-6.5.6.tar.gz tar -xxvf global-6.5.6.tar.gz cd global-6.5.6 ./configure make sudo make install
2.4 ツールのセットアップ
srpm2html.pyは、githubに登録してあるのでそこからダウンロードします。
cd "セットアップしたいディレクトリパスを指定" wget https://gist.githubusercontent.com/Noppy/027ea703dd7084be0c3d4d99ce618109/raw/1e3eefeb83c7542d37c8c455701a0f727df128d4/srpm2html.py chmod +x srpm2html.py
2.5 ディレクトリの準備
デフォルトでは下記ディレクトリが必要になります。ディレクトリは実行時の引数(後述)または、pythonの先頭のデフォルト設定を書き換えることで変更可能です。
- 必要なディレクトリ
- /tmp : srpmのダウンロードと追加するfstabの作成に使用。容量は利用しない。
- /data/rpmbuild : srpmインストール、コード展開、globl解析をするメイン作業用。
- /data/squshfs : 作成したsquashfsファイルの格納先
- /data/kernel : Globalが生成したhtmlのsquashfs化したもののマウントポイントを作成するディレクトリ(kernelのsrpmを解析した場合)
- /data/tools : 上記と同じ(kernel以外の、srpmを解析した場合)
- /data/source:ソースコードをsquashfs化したもののマウントポイントを作成するディレクトリ
2.6 sudo設定
最後のfstab更新とマウント実行時に、sudoコマンドを利用しています。srpm2html.py実行ユーザがsudoでroot昇格できるように設定を事前にして下さい。またパスワード入力が面倒な方は、NOPASSWDもして下さい。
3.使い方
3.1 簡単な使い方
簡単な使い方は以下のとおりです。
./srpm2html.py "SRPMファイルのURL"
例えば、CentOS7.3のカーネルソースを展開したい場合は以下の通りになります。
srpm2html.py http://vault.centos.org/7.3.1611/os/Source/SPackages/kernel-3.10.0-514.el7.src.rpm
3.2 引数の説明
- 構文
usage: srpm_to_html.py [-h] [-d] [-t TMPDIR] [-r RPMBUILDDIR] [-s SQUASHFSDIR] [-K HTTP_KERNELSDIR] [-T HTTP_TOOLSDIR] [-S SOURCEDIR] SRPM_FilePath_or_URL
- 必須引数
- 主なオプション詳細
- -h, --help : ヘルプの表示
- -t TMPDIR, --tmpdir TMPDIR : tmpディレクトリの指定
- -r RPMBUILDDIR, --rpmbuilddir RPMBUILDDIR : srpmの展開先と作業用ディレクトリの指定
- -s SQUASHFSDIR, --squashfsdir SQUASHFSDIR : squashfsファイルの格納先ディレクトリ指定
- -K HTTP_KERNELSDIR, --http_kernelsdir HTTP_KERNELSDIR : マウントポイントを作成するディレクトリ指定(kernel)
- -T HTTP_TOOLSDIR, --http_toolsdir HTTP_TOOLSDIR : マウントポイントを作成するディレクトリ指定(kernel以外)
- -S SOURCEDIR, --sourcedir SOURCEDIR : マウントポイントを作成するディレクトリ指定(ソースコード)
SRPMインストール先を指定する方法
ソースコードをパッケージ化したSRPM(拡張子がsrc.rpmのファイル)のインストール先は、デフォルトでは"${HOME}/rpmbuild"になります。(CentOS5/RHEL5以前は"/usr/src/redhat")。このデフォルトのインストール先を変更する方法を説明します。
1.普通にSRPMをインストールした場合
$rpm -ivh lsof-4.87-4.el7.src.rpm
デフォルトでインストールした場合は、ホームディレクトリ配下のrpmbuildディレクトリにインストールされます。
/home/n/rpmbuild/
├── SOURCES
│ ├── lsof_4.87-rh.tar.xz
│ └── upstream2downstream.sh
└── SPECS
└── lsof.spec
2.インストール先ディレクトリを指定する方法
cloudformation VPC(PubSub x 2, PrivateSub x 2) + 1 Instance(t2.micro, AmazonLinux) を作るテンプレート
概要
自分用のメモです。"一つ前の記事"のVPCのPublicASubにインスタンスを一つ追加したテンプレートです。
作成されるもの
- VPC × 1
- サブネット × 4
- PubASub CIDR:10.0.1.0/24, AZ: ap-northeast-1a ルートテーブル: インターネットへのルーティングあり
- PubBSub CIDR:10.0.2.0/24, AZ: ap-northeast-1c ルートテーブル: インターネットへのルーティングあり
- PrivateASub CIDR:10.0.11.0/24, AZ: ap-northeast-1a
- PrivateBSub CIDR:10.0.12.0/24, AZ: ap-northeast-1c
- セキュリティグループ × 2
- インスタンス × 1
※AZは東京の場合
構成概要

テンプレート
cloudformation VPC(2つのパブリックsub+2つのプライベートsub)を作るテンプレート
概要
自分用のメモです。下記のようなvpcを作るテンプレートです。
作成されるもの
- VPC × 1
- サブネット × 4
- PubASub CIDR:10.0.1.0/24, AZ: ap-northeast-1a ルートテーブル: インターネットへのルーティングあり
- PubBSub CIDR:10.0.2.0/24, AZ: ap-northeast-1c ルートテーブル: インターネットへのルーティングあり
- PrivateASub CIDR:10.0.11.0/24, AZ: ap-northeast-1a
- PrivateBSub CIDR:10.0.12.0/24, AZ: ap-northeast-1c
- セキュリティグループ × 2
※AZは東京の場合
構成概要

テンプレート
ubuntuで古いカーネルを削除する方法(/bootの空きが足りない時とか)
1.はじめに
ubuntuで「ソフトウェアの更新」で「/bootのディスク容量が足りない」と言われてしまった時の対処方法です。
ubuntuが結構頻繁にkernelの更新を行うようで、私は半年ぐらい周期で/bootが足りなくなります。

2.対処方法(古いkernelの削除)
(1)現在のカーネルバージョンの確認
$ uname -r 4.4.0-59-generic
(2)インストール済みカーネルのバージョン一覧を確認
現在利用中のカーネルバージョン(4.4.0-59)以外のバージョン(4.4.0-38、4.4.0-45、4.4.0-47、4.4.0-51、の4つ)をこれから削除します。
$ dpkg --get-selections |grep linux- linux-base install linux-cloud-tools-4.4.0-38 install linux-cloud-tools-4.4.0-38-generic install linux-cloud-tools-4.4.0-45 install linux-cloud-tools-4.4.0-45-generic install linux-cloud-tools-4.4.0-47 install linux-cloud-tools-4.4.0-47-generic install linux-cloud-tools-4.4.0-51 install linux-cloud-tools-4.4.0-51-generic install linux-cloud-tools-common install linux-cloud-tools-generic install linux-firmware install linux-generic install linux-headers-4.4.0-36 install linux-headers-4.4.0-36-generic install linux-headers-4.4.0-38 install linux-headers-4.4.0-38-generic install linux-headers-4.4.0-45 install linux-headers-4.4.0-45-generic install linux-headers-4.4.0-47 install linux-headers-4.4.0-47-generic install linux-headers-4.4.0-51 install linux-headers-4.4.0-51-generic install linux-headers-4.4.0-59 install linux-headers-4.4.0-59-generic install linux-headers-generic install linux-image-4.4.0-36-generic install linux-image-4.4.0-38-generic install linux-image-4.4.0-45-generic install linux-image-4.4.0-47-generic install linux-image-4.4.0-51-generic install linux-image-4.4.0-59-generic install linux-image-extra-4.4.0-36-generic install linux-image-extra-4.4.0-38-generic install linux-image-extra-4.4.0-45-generic install linux-image-extra-4.4.0-47-generic install linux-image-extra-4.4.0-51-generic install linux-image-extra-4.4.0-59-generic install 以下略
(3)コマンドをテスト実行確認(DryーRun)
apt-getコマンドで古いカーネルパッケージを削除します。
”--purge”オプションで削除するパッケージを指定しますが、指定が正しいか確認するため”--dry-run”オプションで空実行させて確認します。
$ sudo apt-get --dry-run autoremove --purge linux-{headers,image}-4.4.0-{36,38,45,47,51}
パッケージリストを読み込んでいます... 完了
依存関係ツリーを作成しています
状態情報を読み取っています... 完了
<省略>
アップグレード: 0 個、新規インストール: 0 個、削除: 39 個、保留: 234 個。
Purg linux-cloud-tools-4.4.0-38-generic [4.4.0-38.57]
Purg linux-cloud-tools-4.4.0-38 [4.4.0-38.57]
Purg linux-cloud-tools-4.4.0-45-generic [4.4.0-45.66]
Purg linux-cloud-tools-4.4.0-45 [4.4.0-45.66]
Purg linux-cloud-tools-4.4.0-47-generic [4.4.0-47.68]
Purg linux-cloud-tools-4.4.0-47 [4.4.0-47.68]
Purg linux-headers-4.4.0-36-generic [4.4.0-36.55]
Purg linux-headers-4.4.0-36 [4.4.0-36.55]
Purg linux-headers-4.4.0-38-generic [4.4.0-38.57]
Purg linux-headers-4.4.0-38 [4.4.0-38.57]
Purg linux-headers-4.4.0-45-generic [4.4.0-45.66]
Purg linux-headers-4.4.0-45 [4.4.0-45.66]
Purg linux-headers-4.4.0-47-generic [4.4.0-47.68]
Purg linux-headers-4.4.0-47 [4.4.0-47.68]
Purg linux-headers-4.4.0-51-generic [4.4.0-51.72]
Purg linux-headers-4.4.0-51 [4.4.0-51.72]
Purg linux-signed-image-4.4.0-36-generic [4.4.0-36.55]
Purg linux-image-extra-4.4.0-36-generic [4.4.0-36.55]
Purg linux-image-4.4.0-36-generic [4.4.0-36.55]
Purg linux-signed-image-4.4.0-38-generic [4.4.0-38.57]
Purg linux-image-extra-4.4.0-38-generic [4.4.0-38.57]
Purg linux-image-4.4.0-38-generic [4.4.0-38.57]
Purg linux-signed-image-4.4.0-45-generic [4.4.0-45.66]
Purg linux-image-extra-4.4.0-45-generic [4.4.0-45.66]
Purg linux-image-4.4.0-45-generic [4.4.0-45.66]
Purg linux-signed-image-4.4.0-47-generic [4.4.0-47.68]
Purg linux-image-extra-4.4.0-47-generic [4.4.0-47.68]
Purg linux-image-4.4.0-47-generic [4.4.0-47.68]
Purg linux-signed-image-4.4.0-51-generic [4.4.0-51.72]
Purg linux-image-extra-4.4.0-51-generic [4.4.0-51.72]
Purg linux-image-4.4.0-51-generic [4.4.0-51.72]
Purg linux-tools-4.4.0-36-generic [4.4.0-36.55]
Purg linux-tools-4.4.0-36 [4.4.0-36.55]
Purg linux-tools-4.4.0-38-generic [4.4.0-38.57]
Purg linux-tools-4.4.0-38 [4.4.0-38.57]
Purg linux-tools-4.4.0-45-generic [4.4.0-45.66]
Purg linux-tools-4.4.0-45 [4.4.0-45.66]
Purg linux-tools-4.4.0-47-generic [4.4.0-47.68]
Purg linux-tools-4.4.0-47 [4.4.0-47.68]4.4.0-36,38,45,47,51の5つのバージョンが選択されていることを確認します。
(4)パッケージを削除する
”--dry-run”オプションを外して削除実行します。
$ sudo apt-get autoremove --purge linux-{headers,image}-4.4.0-{36,38,45,47,51}
(5)削除されたか確認
4.4.0-51以外のバージョンのカーネル削除されたか確認します。
$ dpkg --get-selections |grep linux- linux-base install linux-cloud-tools-4.4.0-51 install linux-cloud-tools-4.4.0-51-generic install linux-cloud-tools-common install linux-cloud-tools-generic install linux-firmware install linux-generic install linux-headers-4.4.0-59 install linux-headers-4.4.0-59-generic install linux-headers-generic install linux-image-4.4.0-59-generic install linux-image-extra-4.4.0-59-generic install linux-image-extra-virtual install linux-image-generic install linux-libc-dev:amd64 install linux-signed-generic install linux-signed-image-4.4.0-59-generic install linux-signed-image-generic install linux-sound-base install linux-tools-4.4.0-51 install linux-tools-4.4.0-51-generic install linux-tools-common install linux-tools-generic install syslinux-common install syslinux-legacy install
3.参考
ansibleのベストプラクティスなplaybookレイアウトを作るシェル
ansibleのベストプラクティスなplaybookディスクレイアウトがあります。
このディレクトリを手動で作成するのが面倒なので簡単なシェルを作成しました。
こんなディレクトリレイアウトとmain.ymlの空ファイルを作成します。
group_vars/
host_vars/
site.yml # master playbook
roles/
RoleName1/ # this hierarchy represents a "role"
tasks/ #
main.yml # <-- tasks file can include smaller files if warranted
handlers/ #
main.yml # <-- handlers file
templates/ # <-- files for use with the template resource
files/ #
vars/ #
main.yml # <-- variables associated with this role
defaults/ #
main.yml # <-- default lower priority variables for this role
meta/ #
main.yml # <-- role dependenciesコードはこちら。
gitの初期設定をしてGitHubからレポジトリをcloneするまでの手順
はじめに
PCを再セットアップした後、いつも設定方法を忘れてgoogleさんに聞いて面倒なので、まとめました。
git初期設定
ユーザ設定&pushモード設定
(1)メールアドレス、(2)名前、(3)push時のモードを指定して、最後に設定内容を確認。
git config --global user.email "xxxxxxx@gmail.com" git config --global user.name "xxxxxxxx" git config --global push.default simple git config --global -l
git認証情報の自動保存設定
# Linuxで認証情報を保存したい場合 git config --global credential.helper store
git Proxy設定(必要があれば)
git config --global http.proxy http://proxy.example.com:3128 git config --global https.proxy http://proxy.example.com:3128
git を使いやすくする設定
コミットログを見やすくするコマンドのエリアス
~/.gitconfigに下記を追加
[alias] lga = log --graph --all --pretty=format:'%C(red)%h %C(reset)-%C(yellow)%d%C(reset) %s %C(green)(%cr) %C(bold blue)<%an>%C(reset)' lg = log --graph --pretty=format:'%C(red)%h %C(reset)-%C(yellow)%d%C(reset) %s %C(green)(%cr) %C(bold blue)<%an>%C(reset)'
- 使い方:
git lga、またはgit lgと実行
GitHubからcloneする
(既存レポジトリがない場合)新規にレポジトリの作成
- "New repository"からレポジトリを作成
- 必要な項目を設定
- レポジトリ名を指定(Repository name)
- "Initialize this repository with a README"をチェック
- "Add .gitignore"で開発したい言語のgitigonreテンプレを選択
- "Add a license"で開発するブツのライセンスを指定(Apache LicenseとかGPLv3とか)
- "Create repository"でレポジトリを作成
レポジトリをcloneする
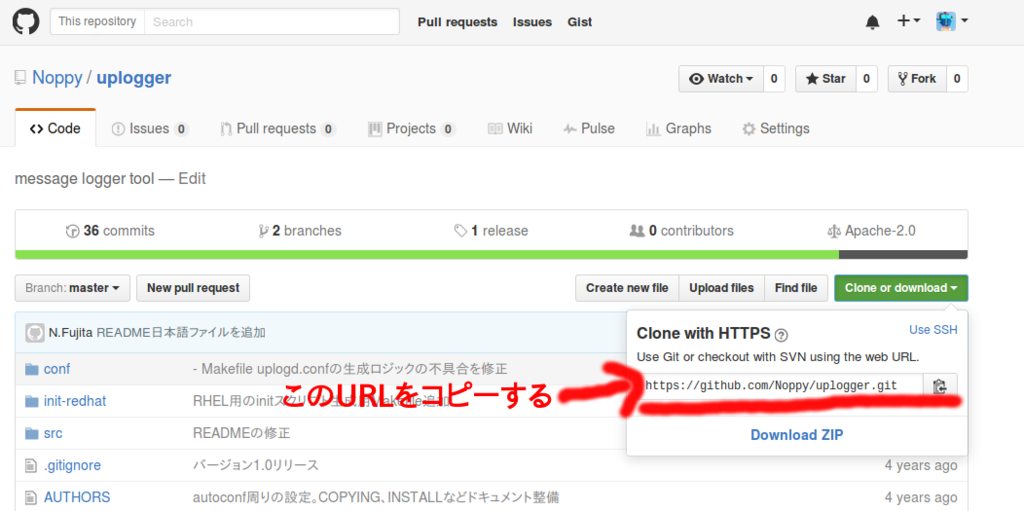
- gitコマンドでcloneする
- 格納したいディレクトリに移動し
- "git clone <コピーしたURL>"でデータをローカルにcloneする
$ git clone https://github.com/Noppy/uplogger.git Cloning into 'uplogger'... remote: Counting objects: 254, done. remote: Total 254 (delta 0), reused 0 (delta 0), pack-reused 254 Receiving objects: 100% (254/254), 382.28 KiB | 226.00 KiB/s, done. Resolving deltas: 100% (141/141), done. Checking connectivity... done.