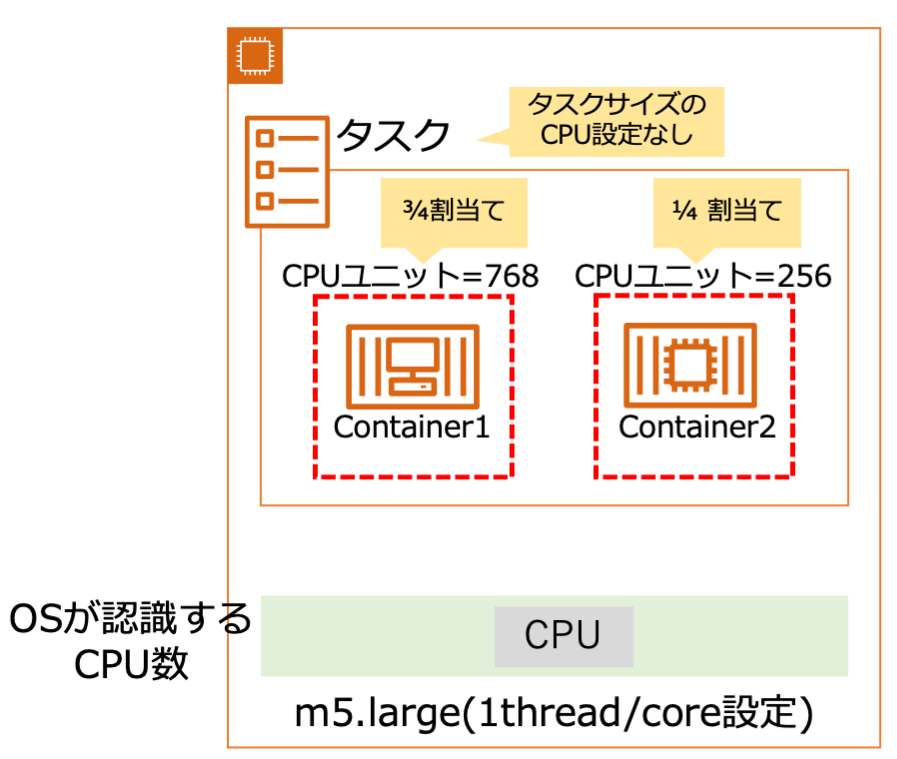
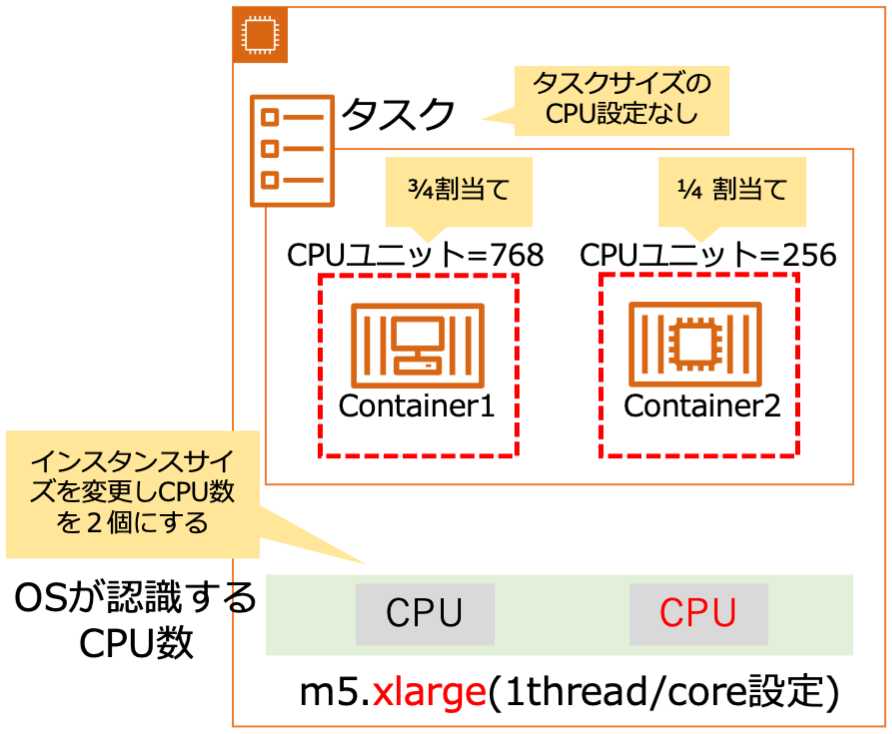
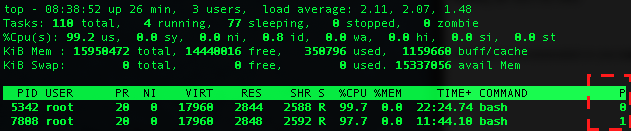
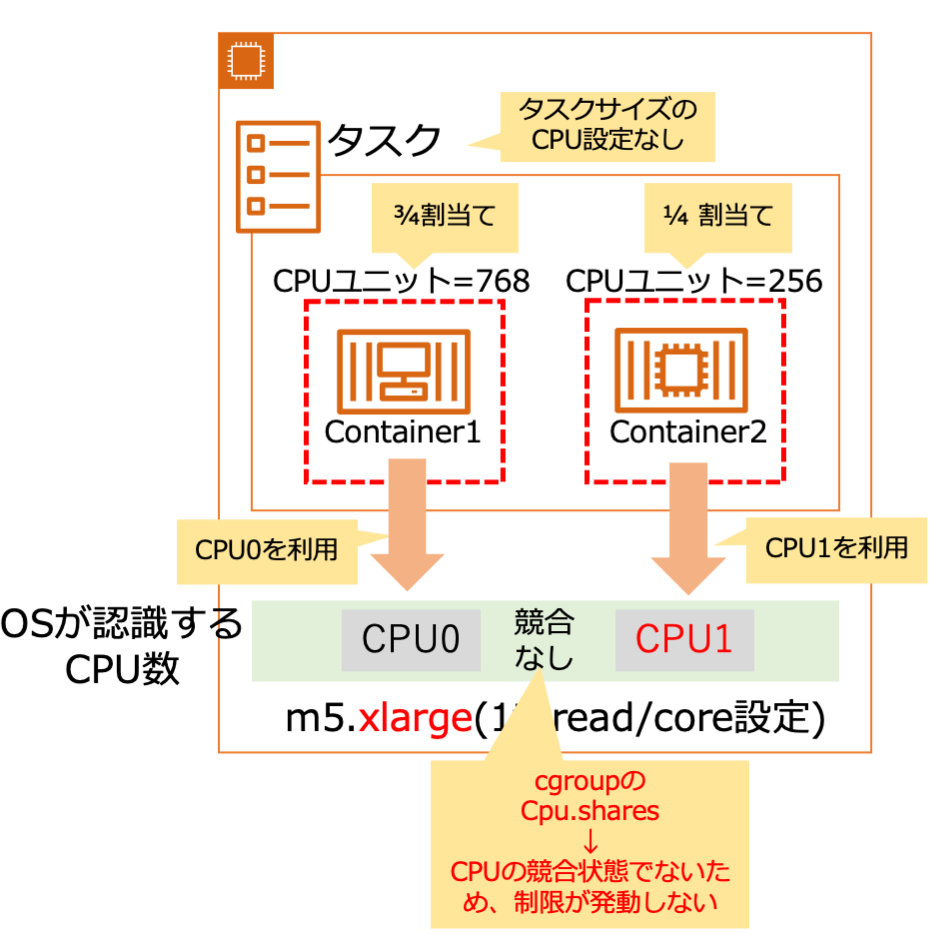
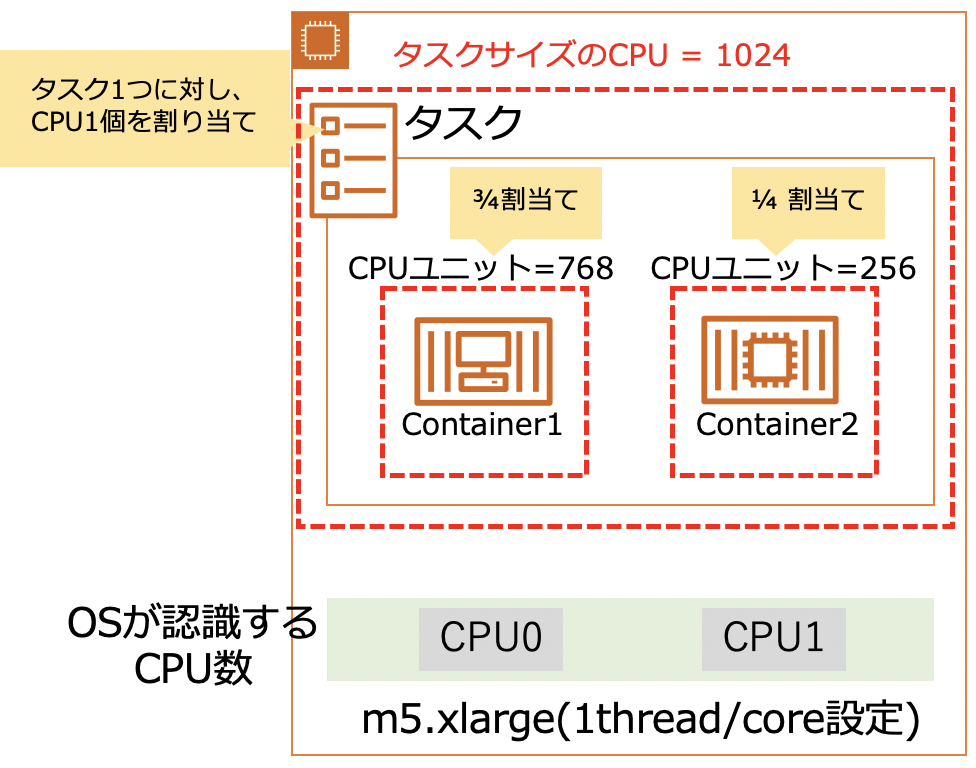
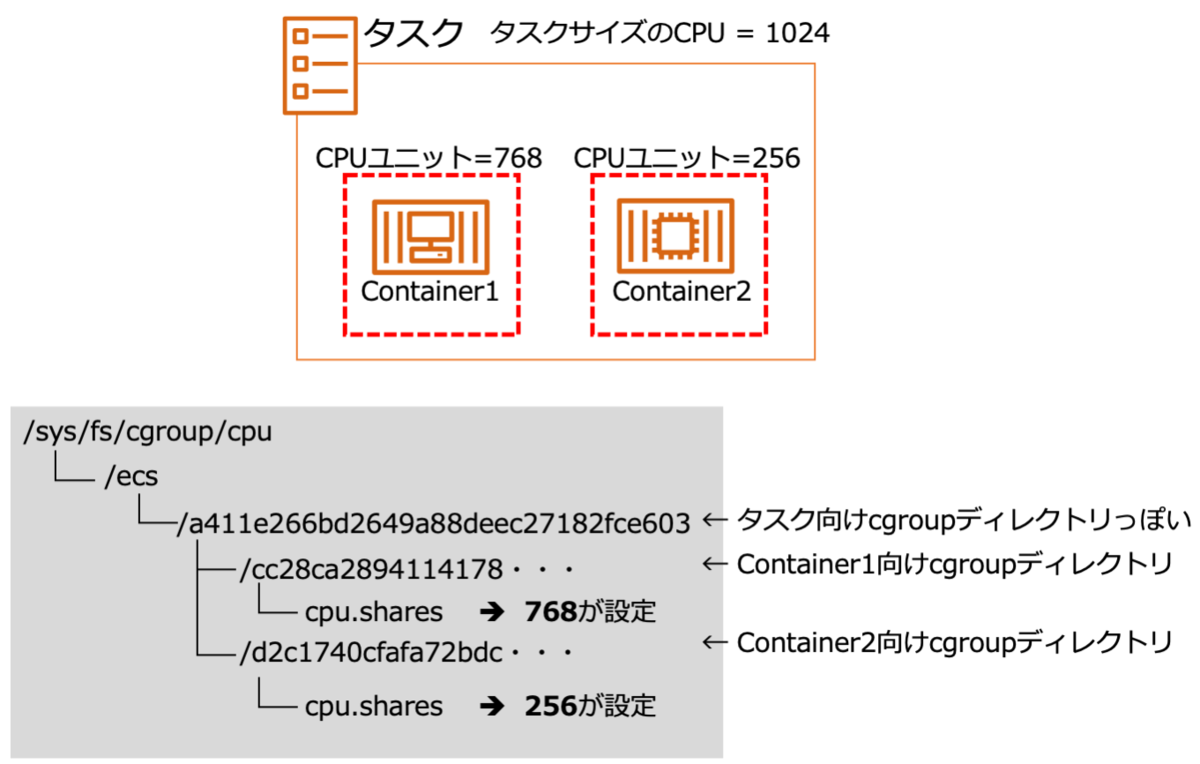
getaddrinfo()実行時のstrace
getaddrinfo()挙動の参考としてstraceによるサンプルコード実行時のシステムコールのトレースを貼り付けます。
$ strace -F -tt ./sample_getaddrinfo google.com
strace: option -F is deprecated, please use -f instead
15:08:38.895790 execve("./sample_getaddrinfo", ["./sample_getaddrinfo", "google.com"], 0x7fff89a8f6b8 /* 22 vars */) = 0
<中略>
<-----------ここからgetaddrinfo()を呼び出した中の処理になります
<中略>
15:08:38.901343 open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 3
↓ <<<nsswitch.confで解決優先順位を確認
15:08:38.901539 fstat(3, {st_mode=S_IFREG|0644, st_size=1713, ...}) = 0
15:08:38.901680 read(3, "#\n# /etc/nsswitch.conf\n#\n# An ex"..., 4096) = 1713
<中略>
↓ <<< /etc/hostsファイルを読み込み確認
15:08:38.902267 open("/etc/host.conf", O_RDONLY|O_CLOEXEC) = 3
15:08:38.906723 fstat(3, {st_mode=S_IFREG|0644, st_size=126, ...}) = 0
15:08:38.907003 read(3, "127.0.0.1 localhost localhost."..., 4096) = 126
<中略>
↓ <<<resolv.confを読み込みでDNSクエリー発行先を取得
15:08:38.902946 open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 3
15:08:38.903064 fstat(3, {st_mode=S_IFREG|0644, st_size=129, ...}) = 0
15:08:38.903266 read(3, "options timeout:2 attempts:5\n; g"..., 4096) = 129
<中略>
↓ <<< UDPによるDNSサーバへの問い合わせ(問い合わせ先 = 10.1.0.2)
15:08:38.911102 socket(AF_INET, SOCK_DGRAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_IP) = 3 <== ここから、DNS(UDP 53port)でDNSにクエリーを発行し応答を受信する処理になります
15:08:38.911335 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.1.0.2")}, 16) = 0
15:08:38.911535 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
15:08:38.911694 sendmmsg(3, [{msg_hdr={msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="8\276\1\0\0\1\0\0\0\0\0\0\6google\3com\0\0\1\0\1", iov_len=28}], msg_iovlen=1, msg_controllen=0, msg_flags=0}, msg_len=28}, {msg_hdr={msg_name=NULL, msg_namelen=0, msg_iov=[{iov_base="\276\316\1\0\0\1\0\0\0\0\0\0\6google\3com\0\0\34\0\1", iov_len=28}], msg_iovlen=1, msg_controllen=0, msg_flags=0}, msg_len=28}], 2, MSG_NOSIGNAL) = 2
15:08:38.912113 poll([{fd=3, events=POLLIN}], 1, 2000) = 1 ([{fd=3, revents=POLLIN}])
15:08:38.912375 ioctl(3, FIONREAD, [44]) = 0
15:08:38.912558 recvfrom(3, "8\276\201\200\0\1\0\1\0\0\0\0\6google\3com\0\0\1\0\1\300\f\0\1"..., 2048, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.1.0.2")}, [28->16]) = 44
15:08:38.912858 poll([{fd=3, events=POLLIN}], 1, 1998) = 1 ([{fd=3, revents=POLLIN}])
15:08:38.913024 ioctl(3, FIONREAD, [56]) = 0
15:08:38.916333 recvfrom(3, "\276\316\201\200\0\1\0\1\0\0\0\0\6google\3com\0\0\34\0\1\300\f\0\34"..., 65536, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.1.0.2")}, [28->16]) = 56
15:08:38.916608 close(3) = 0
<中略>
<-----------ここまでgetaddrinfo()の処理
<中略>
15:08:38.924689 write(1, "addrinfo {\n", 11addrinfo { <== 結果出力
) = 11
15:08:38.924772 write(1, " int ai_flags "..., 39 int ai_flags = 0
) = 39
15: